【Attention】Attention Mechanism Overveiw
Attention and Transformer is salient mechanism in deep learning nowadays. I remain my note which I learn from reference.
0. reference
- a-brief-overview-of-attention-mechanism
- Attention mechanism with schematic
- the development of the attention mechanism
- How Transformers work in deep learning and NLP: an intuitive introduction
1. a-brief-overview-of-attention-mechanism
이 게시물 댓글이 말하길, “이 게시물은 쓰레기다.” 라고 적혀 있다. 딱 아래의 내용만 알자.
- What is Attention?
- hundreds of words -압축-> several words : 정보 손실 발생.
- 이 문제를 해소해주는 방법이 attention. : Attention allow translator focus on local or global feature(문장에 대한 zoom in or out의 역할을 해준다.)
- Why Attention?
- Vanilla RNN : 비 실용적이다. Input의 길이와 Output의 길이가 꼭 같아야 한다. Gradient Vanishing/Exploding가 자주 일어난다. when sentences are long (more 4 words).

- 한 단어씩 차례로 들어가 enbedding 작업을 거쳐서 encoder block에 저장된다, 각 block에는 각각 hidden vector가 존재하고 있다. 4번째 단어가 들어가서 마지막 encoder vertor(hidden vector inside)가 만들어 진다. 그것으로 Decoder가 generate words sequentially.
- Issue : one hidden state really enough?
- Vanilla RNN : 비 실용적이다. Input의 길이와 Output의 길이가 꼭 같아야 한다. Gradient Vanishing/Exploding가 자주 일어난다. when sentences are long (more 4 words).
2. Attention mechanism
이해하기 아주 좋은 게시물 이었다.
- visual attention
- many animals focus on specific parts
- we should select the most pertinent piece of information, rather than using all available information. (전체 이미지 No, 이미지의 일부 Yes)
- Attention 개념은 많은 곳에서 사용된다. 예를 들어서, speech recognition, translation, and visual identification of objects 에서 다 쓰인다.
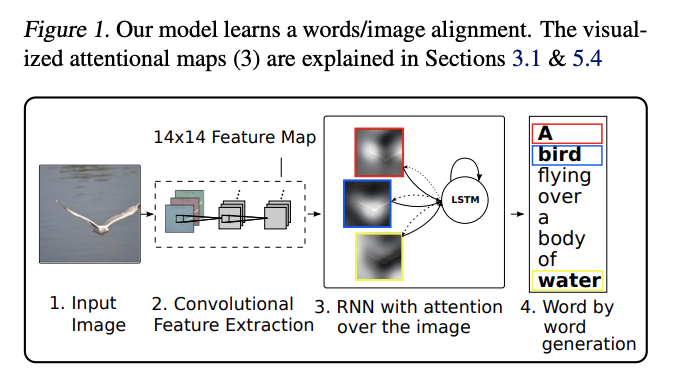
- Attention for Image Captioning
- Basic 이미지 캠셔닝은 아래의 방법을 사용한다. Image를 CNN을 통해서 encoder해서 feature를 얻는데 그게 Hidden state h 가 된다. 이 h를 가지고, 맨 위부터 LSTM를 통해서 첫번째 단어와 h1을 얻고, h와 h1을 LSTM에 넣어서 2번째 단어를 얻는다.

- 나오는 각각의 단어는 이미지의 한 부분만 본다.따라서 이미지 전체를 압축한 h를, 일정 부분만을 보고 결과를 추출해야하는 LSTM에, 넣는 것은 비효율적이다. 이래서 attention mechanism이 필요하다.
- attention mechanism 전체 그림
- What is an attention model? 위의 이미지에서 Attention Model의 내부는 무엇일까?

- attention Model에는 n개의 input이 들어간다. 위의 예시에서 y1 ~ yn이 되겠다.
- 출력되는 z는 모든 y의 summary 이자, 옆으로 들어가는 c와도 연관된 information이다.
- 각 변수의 의미
- C : context, beginning.
- Yi : the representations of the parts of the image. (예를 들어서 이미지 Final feature map의 Channel=n개라면, 1개 Channel을 Yi에 부여한다.)
- Z : 다음 단어 예측을 위한 Image filter 값.
- attention model 분석하기 (저게 최대 화질 이미지..)
- tanh를 통해서 m1,…mn이 만들어 진다. mi는 다른 yj와는 관계없이 생성된다는 것이 중요한 Point이다.
- softmax를 사용해서 각 yi를 얼마나 비중있게 봐야 하는가?에 대한 s1,s2…sn값이 나온다. argmax가 hard, softmax를 soft의 개념이라고 한다.
- 최종 Z는 y1 ,y2 …yn를 s1 ,s2 … sn를 사용해서 the weighted arithmetic mean을 한 것이다.

- 위 전체 과정을 아래와 같이 수정하는 방법도 있다.
- tanh를 dot product로 바꾸기 : any other network, arithmetic(Ex.a dot product) 으로 수정될 수 있다. a dot product 는 두 백터의 연관성을 찾는 것이니, 좀 더 이해하기 쉽다.
- hard attention
- 지금까지 본 것은 “Soft attention (differentiable deterministic mechanism)” 이다. hard attention은 a stochastic process이다. 확률값은 si값을 사용해서 랜덤으로 yi를 선택한다. (the gradient by Monte Carlo sampling)

- 하지만 gradient 계산이 직관적인 Soft Attention를 대부분 사용한다.
- 이 이후에, Z를 사용하는LSTM은, i번째 단어를 예측하고 다음에 집중해야하는 영역에 대한 정보를 담은 h_i+1을 return한다.
- Learning to Align in Machine Translation (언어 모델에서도 사용해보자)
- Image와 다른 점은 attention model에 들어가는 y1,y2 … yi 값은, 문자열이 LSTM을 거쳐나오는 연속적인 hidden layer의 값이라는 것이다.

- Attention model을 들여다 보면, 신기하게도 하나의 input당 하나의 output으로 matcing된다. 이것은 translation 과제에서 장점이자, 단점이 될 수 있다.

3. the development of the attention mechanism

- 핵심 paper
- Seq2Seq, or RNN Encoder-Decoder (Cho et al. (2014), Sutskever et al. (2014))
- Alignment models (Bahdanau et al. (2015), Luong et al. (2015))
- Visual attention (Xu et al. (2015))
- Hierarchical attention (Yang et al. (2016))
- Transformer (Vaswani et al. (2017))
- Sequence to sequence (Seq2Seq) architecture for machine translation
- two recurrent neural networks (RNN), namely encoder and decoder.

- RNN,LSTM,GRU’s hidden state (from the encoder)를 the decoder에 source information 보낸다.
- a fixed-length vector, only last one Hidden state 만을 이용해서 Decoding을 하는 것은 Long sentences issue가 발생할 수 있다.
- RNN으로는 Gradient exploding, Gradient vanishing 문제가 크게 일어난다.
- Align & Translate
- RNN을 한 방향으로만 하지말고, 양방향으로 한다. 이를 통해 얻은 at1, at2… atT를 사용해서, X1..XT 중 어떤것에 더 attetion할지에 대한 정보를 담을 수 있다.
- 아래의 형태 말고도, 논문에는 더 많은 형태의 모델을 제시해놓았다.

- Visual attention
- the image captioning problem 에서 input image와 oput word를 align 하기를 시도 했다.
- CNN으로 feature를 뽑고, 그 정보를 RNN with attention 사용하였다. 위의 #2내용 다시 참조.
- translation 보다 다른 많은 문제에서 attention을 쉽게 적용한 사례중 하나이다.
- Hierarchical Attention
- effectively used on various levels
- attention mechanism 이 classification problem에서도 쓰일 수 있다는 것을 보였다.
- 내가 그림만 보고 이해하기로는 아래와 같은 분석을 할 수 있었다.
- 2개의 Encoder를 사용했다. (word and sentence encoders)

- Transformer and BERT
- paper
- multi-head self-attention : 시간 효율적, representation을 하는데 매우 효율적이다. Convolution, recursive operation을 삭제하기 때문이다. 이 모듈에 대해서는 나중에 공부해볼 예정이다.
- BERT 는 pretrains bi-directional representations with the improved Transformer architecture. 그리고 XLNet, RoBERTa, GPT-2, and ALBERT 와 같은 논문들이 나오는데에 큰 도움을 주었다.
- Vision Transformer
Transformervirtually replaces(대체해 버렸다)convolutional layersrather than complementing(보완하는게 아니라) them- CNN’s golden age. Transformer에 의해서 RNN, LSTM 등이 종말을 마지한 것처럼.
- Conclusion
- attention will be more and more domains welcoming the application
- 추천 논문 : Attention Self-Driving Cars
4. How Transformers work intuitively
- The famous paper “Attention is all you need” in 2017 changed the way we were thinking about attention
- Transformer의 기본 block은 self-attention이다.
- Representing the input sentence (sequential 한 데이터를 포현(함축)하는 방법)
- transformer 의 탄생 배경 : “entire input sequence를 넣어주는거는 어떨까? 단어 단위로 잘라서 (tokenization) sequential 하게 넣어주지 말고!” (RNN과 LSTM과는 다르다. 그들은 sequentially 하게 일을 처리한다.)
- tokenization를 해서 하나의 set을 만든다. 여기에는 단어가 들어가고, 단어간의 order는 중요하지 않다. (irrelevant)
- 집합 내부 단어들을, (대체, 정사하다) project, (words를) in a distributed geometrical space로, 해야한다. (= word embeddings)
- (1) Word Embeddings
- character <- word <- sentence와 같이 distributed low-dimensional space로 표현하는 것.
- 단어들은 각각의 의미만 가지고 있는게 아니라, 서로간의 상관관계를 가지기 때문에 3차원 공간상에 word set을 뿌려놓으면 비슷한 단어는 비슷한 위치에 존재하게 된다. visualize word Embeddings using t-SNE
- 단어 임배딩이 무엇이고 어떻게 구현하는가 : 특정 단어를 4차원 백터로 표현하는 방법

- “이런게 있구나” 정도로만 이해했다. 어차피 내가 NLP 할 것은 아니니까.
- (2) Positional encodings

- 위에서는 단어의 order를 무시한다고 했다. 하지만 order (in a set) 을 모델에게 알려주는 것은 매우 중요하다.
- positional encoding : word embedding vector에 추가해주는 set of small constants(작은 상수) 이다.
- sinusoidal function (sin함수) 를 positional encoding 함수로 사용한다.
- sin함수에서 주파수(y=sin(fx), Cycle=2pi/f)와 the position in the sentence를 연관시킬 것이다.
- 예를 들어보자. (위의 특정 단어를 4차원 백터로 표현한 그림 참고)
- 만약 32개의 단어가 있고, 각각 1개의 단어는 512개의 백터로 표현가능하다.
- 아래와 같이 1개 단어에 대한 512개의 sin(짝수번쨰단어),cos(홀수번째단어)함수 결과값을 512개의 백터 값으로 표현해주면 되는 것이다.

- 이런 식으로 단어를 나타내는 자체 백터에 에 순서에 대한 정보를 넣어줄 수 있다.
- 예를 들어, 영어사전 안에 3000개의 단어가 있다면 3000개의 단어를 각각 2048개의 백터로 표현해 놓는다. 프랑스어사전 안에서 그에 상응하는 3000개의 단어를 추출하고, 단어 각각 2048개의 백터로 임배딩 해놓는다. 그리고 아래의 작업을 한다고 상상해라.
- Encoder of the Transformer
- Self-attention & key, value query

- 매우 추천 동영상, Attention 2: Keys, Values, Queries : 위의 Attention Mechanism을 다시 설명해 주면서, key values, Query를 추가적으로 설명해준다.
- 위의 ‘What is an attention model’ 내용에 weight 개념을 추가해준다. C,yi,si 부분에 각각 Query, key, Value라는 이름의 weight를 추가해준다.
- NER = Named Entity Recognition : 이름을 보고, 어떤 유형인지 예측하는 test. Ex.아름->사람, 2018년->시간, 파리->나라
- 직관적으로 이해해보자. ‘Hello I love you’라는 문장이 있다고 치자. Love는 hello보다는 I와 yout에 더 관련성이 깊을 것이다. 이러한 관련성, 각 단어에 대한 집중 정도를 표현해 주는 것이, 이게 바로 weight를 추가해주는 개념이 되겠다. 아래의 그림은 각 단어와 다른 단어와의 관련성 정도를 나타내주는 확률 표 이다.

- Multi Head Attention
- 참고 동영상, Attention 3: Multi Head Attention
- I gave my dog Charlie some food. 라는 문장이 있다고 치자. 여기서 gave는 I, dog Charlie, food 모두와 관련 깊은데, 이게 위에서 처럼 weight 개념을 추가해 준다고 바로 해결 될까?? No 아니다. 따라서 우리는 extra attention 개념을 반복해야 한다.

- Short residual skip connections
- 블로그의 필자는, 아래의 Skip Connection구조를 직관적으로 이렇게 설명한다.
- 인간은 top-down influences (our expectations) 구조를 사용한다. 즉 과거의 기대와 생각이 미래에 본 사물에 대한 판단에 영향을 끼지는 것을 말한다.
- Layer Normalization, The linear layer 을 추가적으로 배치해서 Encoder의 성능을 높힌다.

- Self-attention & key, value query
- Decoder of the Transformer
- DETR 와 Vit 논문안에 있는 내용 참조
- Attention 4 - Transformers
- Multi-head attention is a mechanism to add context that’s not based on RNN

- 아래 사진은 그냥 기본적인 내용의 설명 그림.

- Input에는 문장이 들어가고, Multi-head Attention에서 각 단어에 대한 중요성을 softmax(si)로 계산 후, 그것을 가중치 wi로 두고, 원래 단어와 곱해놓는다. (What is an attention model?의 사진 참조)
- Multi-head Attention doesn’t care about position. But Positional Enxoding push to care more about position.
- Why Multi-head Attention can be replaced RNN

