【Paper】 convolutional Block Attention Module - Paper Summary
CBAM : Convolutional Block Attention Module
0. Abstract
- our module sequentially infers attention maps along two separate dimensions
- the attention maps are multiplied to the input feature map for adaptive feature refinement (향상되어 정제된 feature)
- lightweight and general module, it can be integrated into any CNN architectures
1. introduction
- Recent Detectors
- recent researches have mainly investigated depth, width(#channel), and cardinality(같은 형태의 빌딩 블록의 갯수).
- VGGNet, ResNet, GoogLeNet has become deeper for rich representation(중요한 특징 표현력).
- GoogLeNet and Wide ResNet(2016), width must be another important factor.
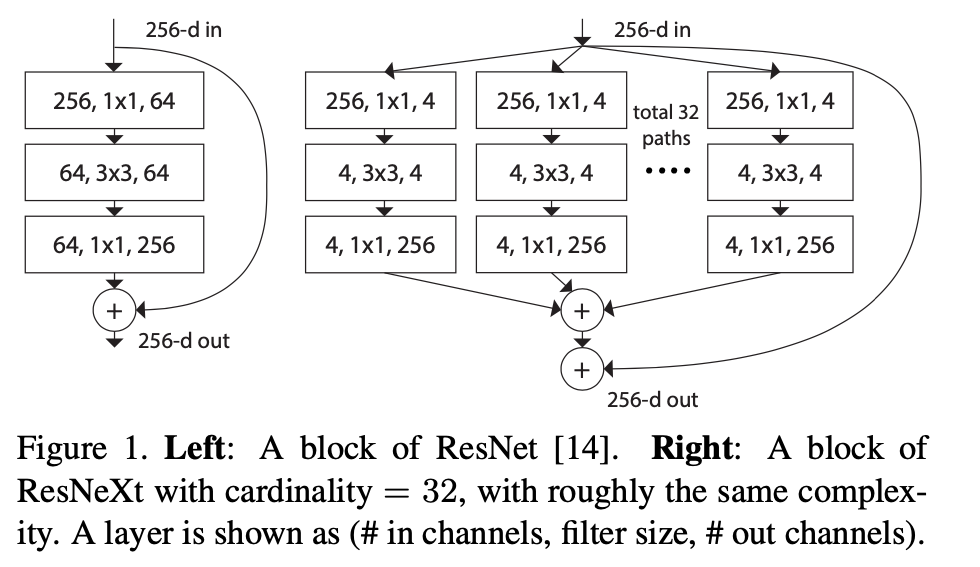
- Xception and ResNeXt, increase the cardinality of a network . the cardinality saves the total number of parameters and make results powerful than depth and width.
- significant visual attention papers
- [16] A recurrent neural network for image generation
- [17] Spatial transformer networks
- Emphasize meaningful features / along those two principal dimensions / channel(depth) and spatial axes(x,y). -> channel and spatial attention modules -> learning which information to emphasize or suppress.
- Contribution
- Can be widely applied to boost representation power of CNNs
- Extensive ablation studies
- Performance of various networks is greatly improved
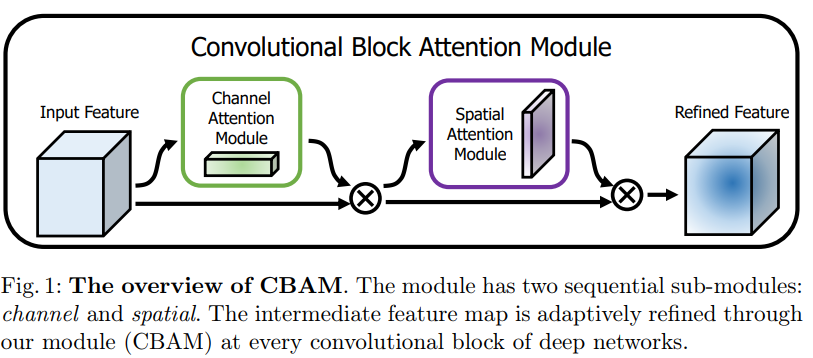
2. Related Work
Network engineering
- ResNet / ResNeXt / Inception-ResNet
- WideResNet : a larger number of convolutional filters and reduced depth
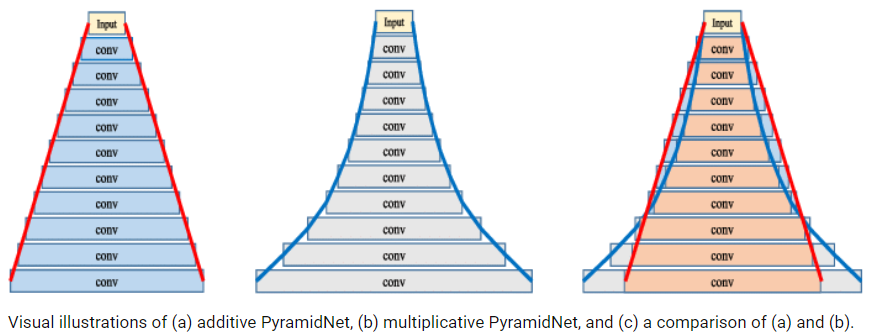
- PyramidNet : a strict generalization of WideResNet and the width increases.
- ResNeXt : use grouped convolutions and vertify cardinality effect
- DenseNet : Concatenates the input features with the output features
Attention
- (2017) Residual attention network for image classification
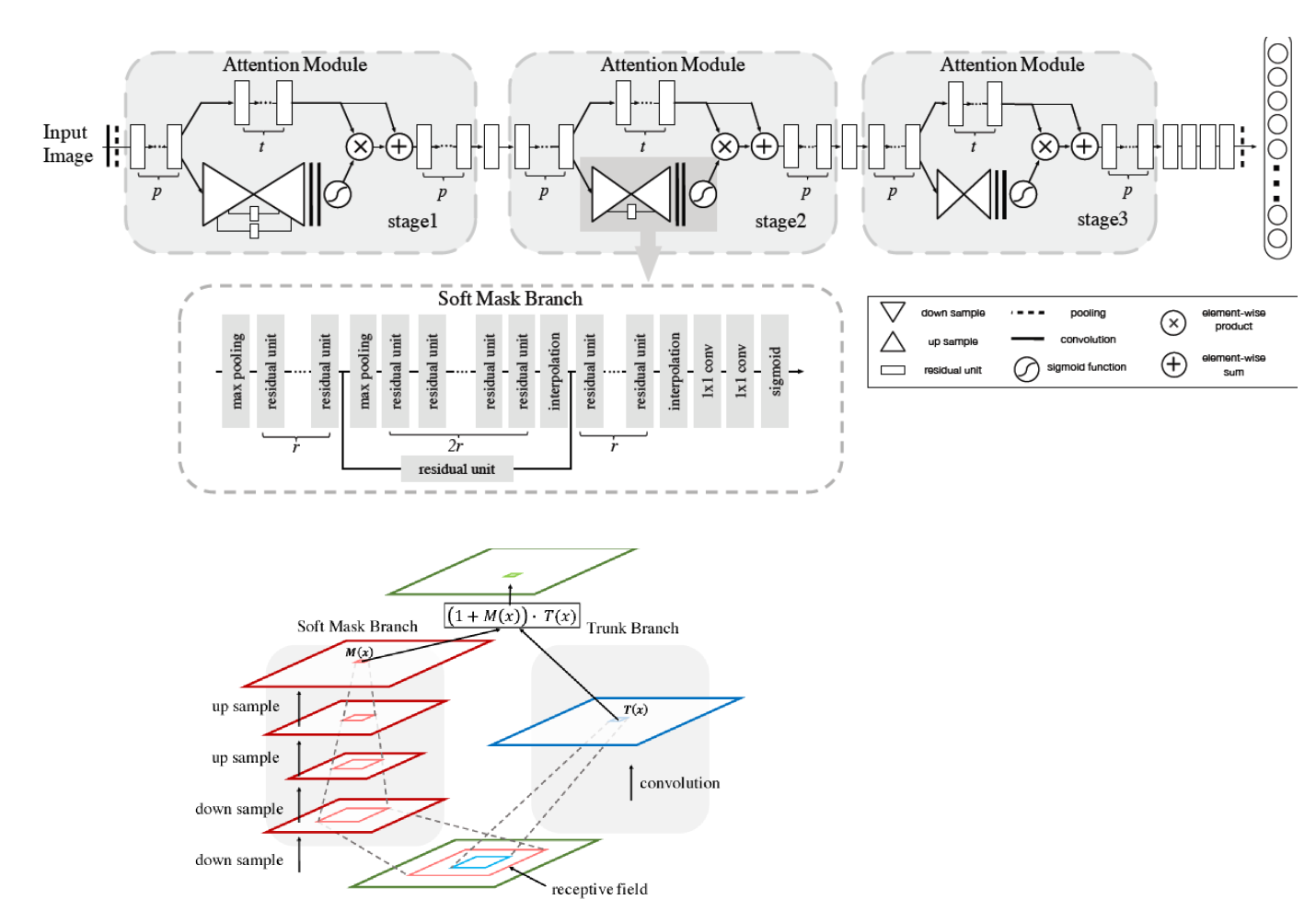
- encoderdecoder style attention module
- By refining the feature maps, performance good, robust to noisy inputs
- more computational and parameter
- (2017) Squeeze-and-excitation networks

- Exploit the inter-channel relationship
- global average-pooled features to compute channel-wise attention. (‘what’ to focus) -> we suggest to use max-pooled features.
- miss the spatial attention deciding ‘where’ to focus.
- (2019) Spatial and channel-wise attention in convolutional networks for image captioning
- (2017) Residual attention network for image classification

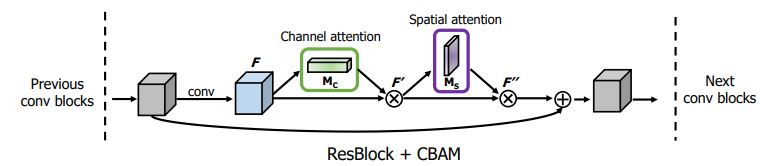
3. Convolutional Block Attention Module
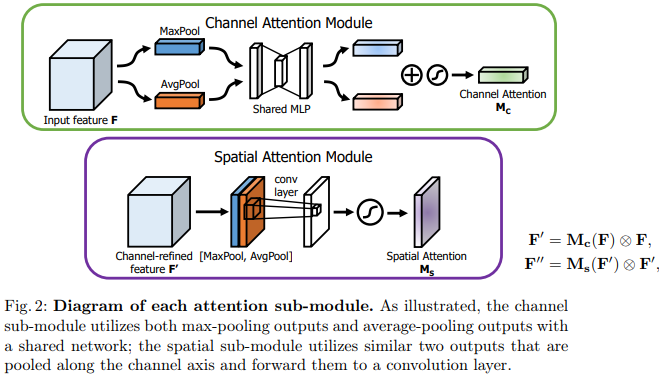
- ⊗ : element-wise multiplication
channel attention values are broadcasted along the spatial dimension
Channel attention module
- In the past, make model learn the extent of the target object or compute spatial statistics.[33] [28]
- exploiting the inter-channel relationship of features.
- each channel is considered as a a feature detector.
- ‘what’ is meaningful
- average pooling and max-pooling -> two different spatial context (F^c_avg and F^c_max)
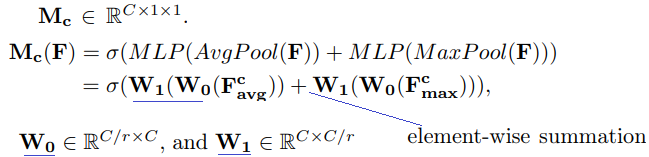
- W1, W0 are shared for both inputs and the ReLU activation function is followed by W0. r = reduction ratio.
Spatial attention module
- The design philosophy is symmetric with the channel attention branch.
- [34] Paying more attention to attention, pooling along channel axis can be effective in highlighting informative regions.
- concatenated feature (both descriptor)
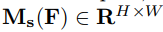 : encodes where to emphasize or suppress.
: encodes where to emphasize or suppress.
- σ : the sigmoid function, the filter size of 7 × 7
Arrangement of attention modules
- the sequential arrangement gives a better result than a parallel arrangement. (첫번째 그림처럼. 직렬로. width하게 병렬로 NO)
- our experimental result.
4. Experiments
- We apply CBAM on the convolution outputs in each block
- top-5 error, top-1 error : 감소해야 좋음
- FLOPS = FLoating point Operations Per Second
GFLOPS = GPU FLoating point Operations Per Second
(그래픽카드의 소요 정도) - we empirically show the effectiveness of our design choice.
- FLOPS = FLoating point Operations Per Second
GFLOPS = GPU FLoating point Operations Per Second
(그래픽카드의 소요 정도) - Channel attention
- a shared MLP
- using both poolings
- r = the reduction ratio to 16.
- Spatial attention
- channelpooling
- convolution layer with a large kernel size
- Arrangement
- FLOPS = FLoating point Operations Per Second
4.2 Image Classification on ImageNet-1K
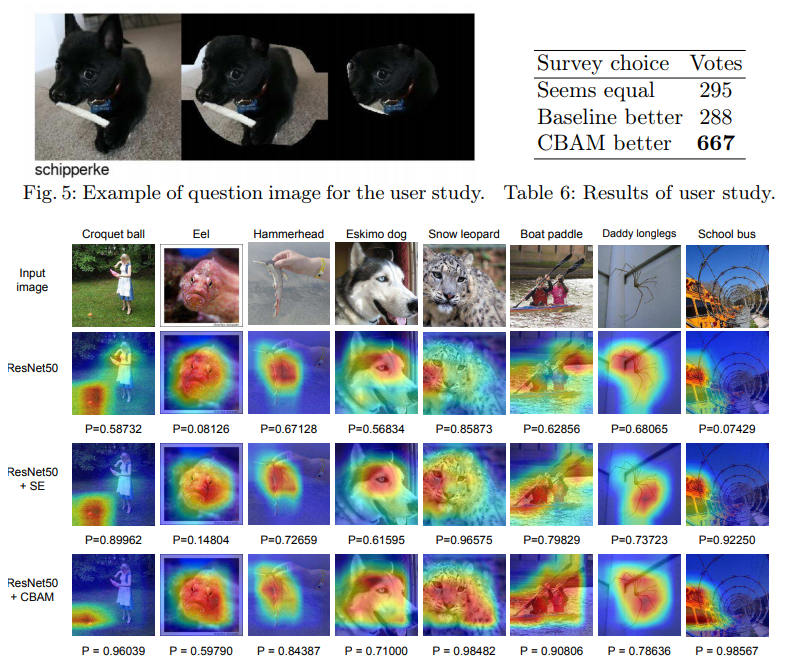
4.3 Network Visualization with Grad-CAM
- Grad-CAM is a recently proposed visualization method.
- Grad-CAM uses gradients in order to calculate the importance of the spatial locations.
5. conclusion
- we observed that our module induces the network to focus on target object properly.
- We hope CBAM become an important component of various network architectures.
모르는 내용
- Visualize whether trained models is efficient, the Grad-CAM [18]
- Top-down semantic aggregation for accurate one shot detection [30]
- GFLOPs / Top-1 Error / Top-5 Error
