【Paper】 Image Segmentation Using Deep Learning -A Survey [3]
Image Segmentation Using Deep Learning: A Survey 논문 리뷰 및 정리
(위성Segment) Segmentation Survey 논문 정리 3 논문 원본 : 2020 (cite:6) Image Segmentation Using Deep Learning: A Survey
Section 4: IMAGE SEGMENTATION DATASETS
- 이 세션에서는 이미지 세그먼테이션 데이터 세트에 대한 요약을 제공한다
- 2가지 범주로 분류 : 2D 이미지, 3D 이미지, 2.5 이미지(depth카메라)
- 일부 데이터셋에서는 data augmentation을 하는 것이 좋다.(특히 의료 이미지에서) 그 방법으로는 reflection, rotation, warping, scaling, color space shifting, cropping, and projections onto principal components과 같은 방법이 있다.
- data augmentation를 통해서 모델의 성능을 향상시키고, 수렴 속도를 높히고, Overfitting 가능성을 줄이며, 일반화 성능을 향상시키는데 도움이 될 수 있다.
4.1 - 2D Datasets
- PASCAL Visual Object Classes (VOC) [141]
- 5가지 정보 : classification, segmentation, detection, action recognition, and person layout
- 21가지 segmentation class
- 각각 1,464, 1,449개의 Train, Validation 이미지
- PASCAL Context [142]
- PASCAL VOC의 확장데이터
- 400개의 segmentation class {divided into three categories (objects, stuff, and hybrids)}
- 하지만 너무 희박하게 존제하는 data 때문에 사실상, 59개의 자주 나타나는 class로 일반적으로 적용된다.
- Microsoft Common Objects in Context (MS COCO) [143]
- dataset : 91 objects types / 2.5 million labeled instances / 328k images
- segmenting individual object instances
- detection : 80 classes / 82k train images / 40.5k validation / 80k test images
- Cityscapes [144]
- semantic understanding of urban street scenes에 집중되어 있다.
- diverse set of stereo video sequences / 50 cities / 25k frames
- 30 classes(grouped into 8 categories)
- ADE20K[134] / MIT Scene Parsing (SceneParse150)
- scene parsing algorithms을 위한 training and evaluation platform
- 20K images for training/ 2K images for validation / 150 semantic categories
- SiftFlow [145]
- 2,688개의 정보 있는 이미지
- 258*258이미지
- 8 가지 풍경(산 바다 등.. ) / 33 semantic classes
- Stanford background [146]
- 하나 이상의 forground(객체)가 있는 715 images
- BSD (Berkeley Segmentation Dataset) [147]
- 1,000 Corel dataset images
- empirical basis(경험적 기초) for research on image segmentation
- 공개적으로 흑백이미지, 칼라이미지 각각 300개가 있다.
- Youtube-Objects [148], [149]
- 10 개의 PASCAL VOC class에 대한 동영상 데이터(weak annotations) [148]
- 10,167 annotated 480x360 pixel frame [149]
- KITTI [150]
- mobile robotics and autonomous driving에서 자주 쓰이는 데이터 셋
- hours of videos(high-resolution RGB, grayscale stereo cameras, and a 3D laser scanners)
- original dataset에서는 ground truth for semantic segmentation를 제공하지 않는다.
- 그래서 직접 annotation한 데이터 셋으로 [151]에서 323 images from the road detection challenge with 3 classes(road, vertical(빌딩, 보행자 같은), and sky)
- 그 외 추가 데이터 셋
- Semantic Boundaries Dataset (SBD) [152]
- PASCAL Part [153]
- SYNTHIA [154]
- Adobes Portrait Segmentation [155]

4.2 - 2.5D Datasets
- RGB-D 이미지는 비교적 저렴한 방법으로 데이터를 얻을 수 있기 때문에 많은 분야에서 사용되고 있다.
- NYU-D V2 [156]
- the RGB and depth cameras of the Microsoft Kinect
- 1,449개의 labeled 이미지. 3개의 도시
- instance number가 기록되어 있다.
- 407,024 unlabeled frames
- SUN-3D [157]
- RGB-D video dataset
- SUN RGB-D [158]
- an RGB-D benchmark for the goal of advancing the state-of-the-art
- four different sensors / 10,000 RGB-D images
- 2D polygons / 3D bounding boxes
- UW RGB-D Object Dataset [159]
- a Kinect style 3D camera.
- 51 categories / 640 480 pixel RGB and depth images at 30 Hz
- ScanNet [160]
- an RGB-D video dataset
- nstance- level semantic segmentations
- 3D scene understanding tasks에서 사용.
- 3D object classification, semantic voxel labeling, and CAD model retrieval.에서도 사용된다.

4.3 - 3D Datasets
- robotic, medical image analysis, 3D scene analysis, construction applications(공사 응용)에 사용되는 3D이미지 데이터셋을 살펴본다.
- 3D datasets은 point clouds와 같이, meshes or other volumetric representations(표현법)으로 제공된다.
- Stanford 2D-3D [161]
- instance-level semantic and geometric annotations from 2D, 2.5D and 3D
- 6 indoor areas
- 70,000 RGB images along with the corresponding depths, surface normals, semantic annotations, global XYZ images as well as camera information.
- ShapeNet dataset [162] [163]
- single clean 3D models
- 55 common object categories with about 51,300 unique 3D models
- Sydney Urban Objects Dataset [164]
- urban road objects of Sydney, Australia.
- vehicles, pedestrians, signs and trees
Section 5: PERFORMANCE REVIEW
- segmentation models의 성능을 평가하기 위해서, 사용하는 popular metrics(업무 수행 결과를 보여주는 계량적 분석)을 몇가지 소개해준다.
- 유망한 DL-based segmentation models에 대한 정량적 성능표도 제공한다.
- 모델을 평가하기 위해서는 많은 요소를 보아야한다. Ex. quantitative accuracy, speed (inference time), and storage requirements (memory footprint)
5.1 Metrics For Segmentation Models
여기에서는 the accuracy of segmentation을 평가하기 위한 몇가지 metrics을 소개한다.

- Pixel accuracy - 식(2)
- 모든 픽셀 중 잘 segmentation한 픽셀의 비율
- 식에서 K는 클래스의 갯수. K+1은 forground 추가
- ground truth : class j / 예측한 class : i
- 이것을 모든 클래스에 대해서 평균낸 것이 MPA(Mean Pixel Accuracy)이다. - 식(3)
- Intersection over Union (IoU) == the Jaccard Index - 식(4)
- Mean-IoU : the average IoU over all classes. Sementation모델의 성능을 평가하기 위해 많이 사용되고 있다.
- Precision / Recall - 식(5) : 참조링크
- TP : the true positive fraction (클래스를 맞게 예측한 갯수)
- FP : the false positive fraction (클래스를 틀리게 예측한 갯수)
- FN : the false negative fraction (한 클래스에 대해서, 틀리게 예측한 갯수)
- F1 score - 식(6)
- precision & recall를 조화롭게 해놓은 mean
- Dice coefficient - 식(7)
- IOU와 비슷하지만 다른 식이다. 비교해서 확인해보기.
- Dice coefficient about foreground - 식(8)
- binary segmentation maps(배경이냐? 객체냐?)
- a positive class로써 foreground라고 생각하고, Dice 식을 쓰면 F1과 같은 식이 된다.
5.2 Quantitative Performance of DL-Based Models
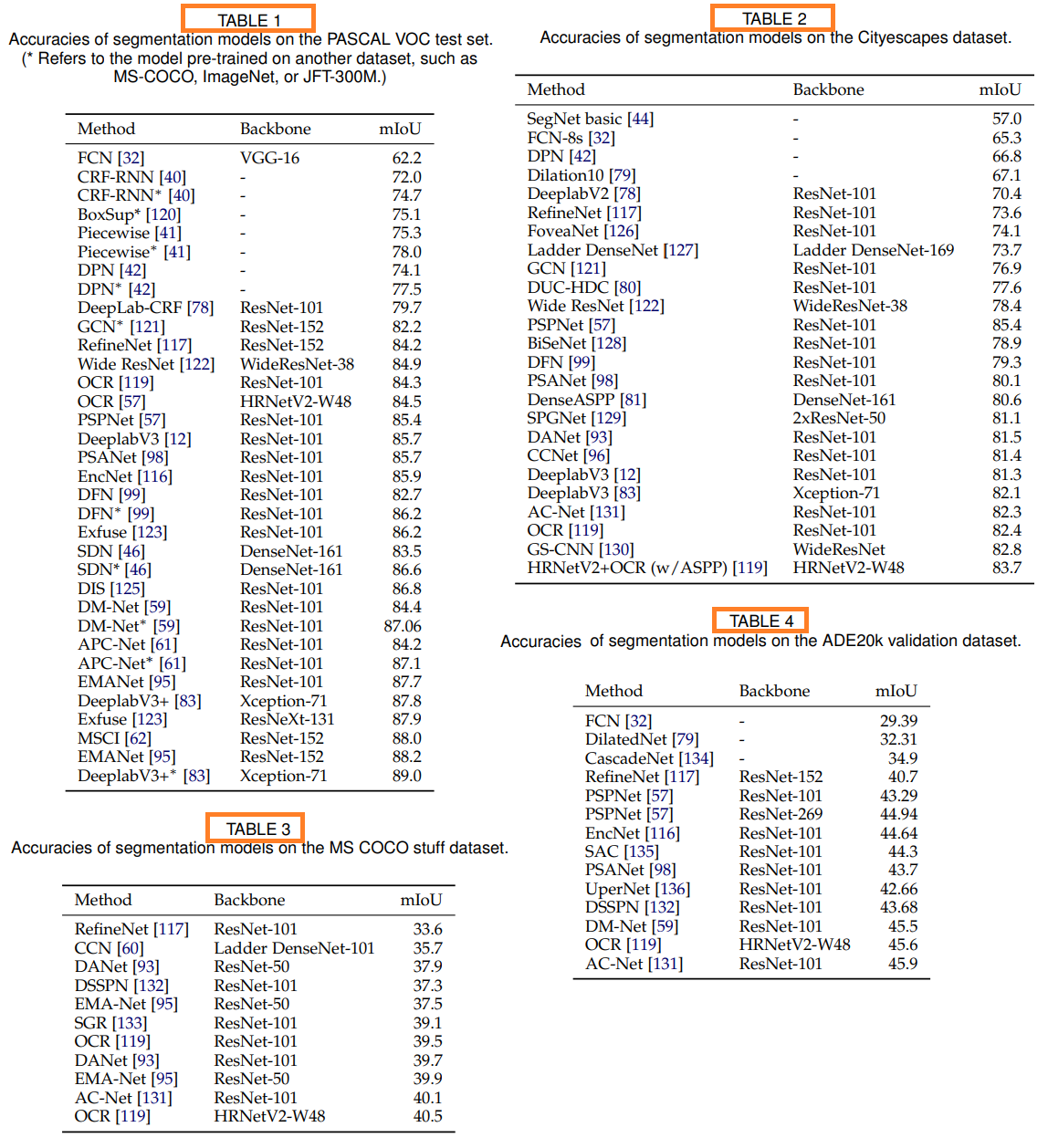
- Table1 : the PASCAL VOC
- Table2 : the Cityscape test dataset
- Table3 : the MS COCO stuff test set
- Table4 : the ADE20k validation set
Table5 : the NYUD-v2 and SUNRGBD datasets for RGB-D segmentation (논문 참조)
- 대부분의 모델에서 코드를 제공하지 않기 때문에, 논문의 내용을 재현하기 위해 많은 노력을 투자했다.
- 일부 논문에서는 1. performance on non-standard benchmarks, 2. performance only on arbitrary subsets of the test set from a popular benchmark를 발표하고, 적절하고 완벽한 설명을 제공하지 않기 때문에, 실험이 쉽지 않았다.
section 6: CHALLENGES AND OPPORTUNITIES
- 앞으로 Image segmentation 기술을 향상시키기 위한, 몇가지 유망한 연구방향을 소개한다.
6.1 More Challenging Datasets
- large-scale image datasets이 많이 있지만, 더 까다로운 조건과 다양한 종류의 데이터가 필요하다.
- 객체가 매우 많고나 객체들이 overlapping되어 있는 이미지들이 매우 중요하다.
- 의료 이미지에서 더 많은 3D이미지 데이터셋이 필요하다.
6.2 Interpretable Deep Models
- 성능이 좋은 모델들은 많지만, what exactly are deep models learning? / How should we interpret the features learned by these models? 에 대한 답변을 정확히 하지 못하고 있다.
- 모델들의 구체적인 행동을 충분히 이해하는 연구가 필요하다. 이러한 이해는 더 좋은 모델을 개발하는데 큰 도움을 줄 것이다.
6.3 Weakly-Supervised and Unsupervised Learning
- Weakly-supervised (a.k.a. few shot learning)과 unsuper- vised learning은 매우 각광 받고 있는 연구이다. 이 연구를 통해서 Segmentation에서 labeled dataset을 받는데 큰 도움을 받을 수 있을 것이다(특히 의료 분야에서).
- The transfer learning(유명한 데이터 셋을 이용해 학습시킨 모델을 이용해 나의 데이터 셋에 맞게 fine-tune하는 것) 과 같이, Self-supervised learning도 우리에게 크게 유용할 것 이다. Self-supervised learning을 통해서 훨씬 적은 수의 데이터셋을 이용해서 Segmentation 모델을 학습시킬 수 있다.
- 지금은 강화학습을 기반한 Segmentation 모델이 나오고 있지 않지만, 미래에 좋은 기반 방법이 될 수 있을 것이다.
6.4 Real-time Models for Various Applications
- 최소 25프레임 상의 segmentation 모델을 가지는 것이 중요하다.
- 이것은 자율주행자동차와 같은 컴퓨터 vision 시스템에 매우 유용할 것이다.
- 현재 많은 모델들은 frame-rate와 거리가 멀다.
- dilated convolution은 the speed of segmentation models을 올리는데 큰 도움을 주지만, 그래도 여전히 개선시켜야할 요지는 많다.
6.5 Memory Efficient Models
- 많은 모델들은 inference를 하는데도 많은 메모리를 필요로 한다.
- 휴대폰과 같은 장치에도 적합한 모델을 만들려면 네트워크를 단순화해야한다.
- simpler models/ model compression techniques/ knowledge distillation techniques등을 사용해서 더 작은 메모리로 더 효율적으로 복잡한 내트워크를 수정할 수 있다.
6.6 3D Point-Cloud Segmentation
- 3D 포인트 클라우드 세그멘테이션을 다루는 사람은 훨씬 적다. 하지만 그 관심이 점점 높아지고 있다. 특히 3D modeling, self-driving cars, robotics, building modeling에서.
- 3D unordered and unstructured data를 처리하기 위해서 CNNs and other classical deep learning architectures를 적용하는것이 가장 좋은 방법인지는 확실하지 않다.
- Graph-based deep models이 3D point-cloud segmentation를 다루는데에 좋을 수도 있다.
- point-cloud segmentation이 가능하다면 많은 산업적 응용이 가능할 것이다.
7 CONCLUSIONS
- 우리는 100개 이상의 Image segmentation모델을 비교해보았다.
