【강화학습】 CS285 Lecture 5 정리노트
(강화학습) CS285 Lecture 5 정리노트
**BackGround
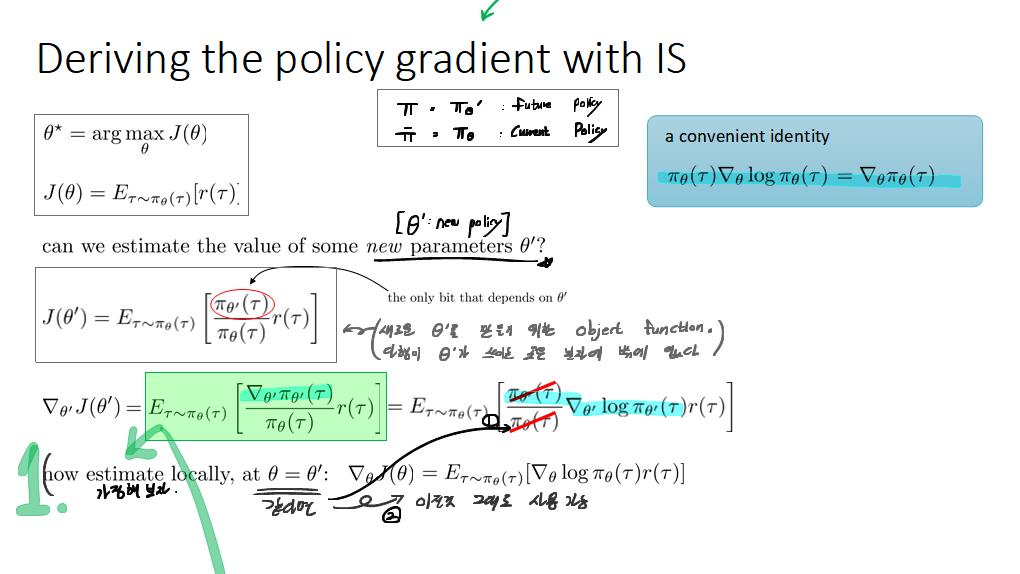
통계 및 머신 러닝 문제에서 많은 경우는 어떠한 확률 분포 p의 기댓값 (expected value)을 구하는 것(샘플들을 추출해, 그 샘플에 대한 실험을 하고 실험한 결과를 평균을 낸다.)과 밀접한 연관이 있다. Importance sampling은 효율적으로 기댓값을 추정하기 위해 고안되었으며, 확률 밀도 추정 및 강화 학습 등의 다양한 활용에 이용되고 있다. Importance sampling의 목적은 기댓값을 계산하고자 하는 확률 분포 p(x)의 확률 밀도 함수 (probability density function, PDF)를 알고는 있지만 p에서 샘플을 생성하기가 어려울 때, 비교적 샘플을 생성하기가 쉬운 q(x)에서 샘플을 생성하여 p의 기댓값을 계산하는 것이다. 우리는 [식 1]과 같이 q에서 생성된 샘플을 이용하여 p의 기댓값을 계산할 수 있다.

[식 1]에서 p(x)/q(x)를 likelihood ratio라고 하며, p를 nominal distribution, q를 importance distribution이라고 한다. Importance sampling에서는 p의 기댓값 Ex∼p[f(x)]를 [식 2]와 같이 추정한다.

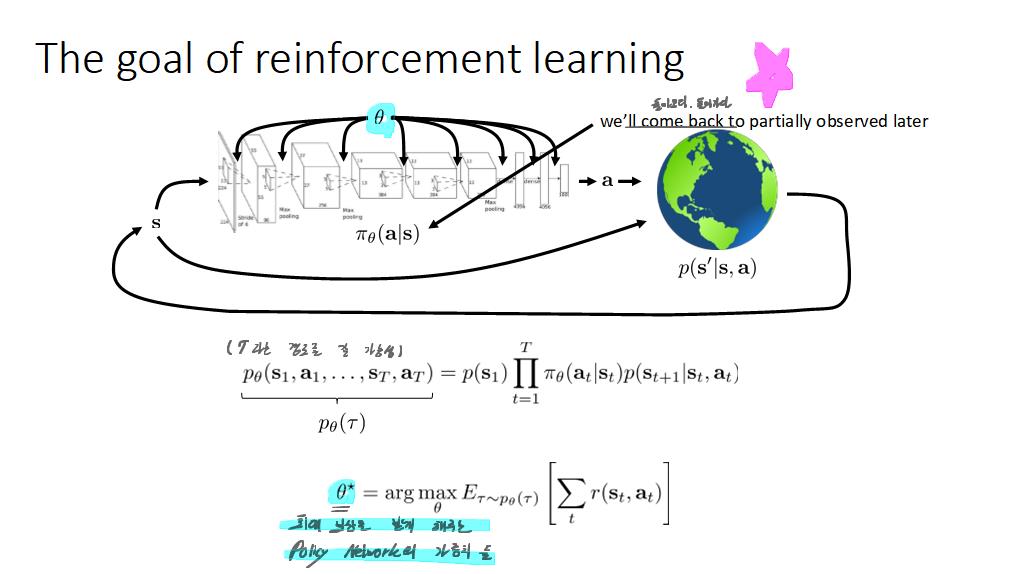
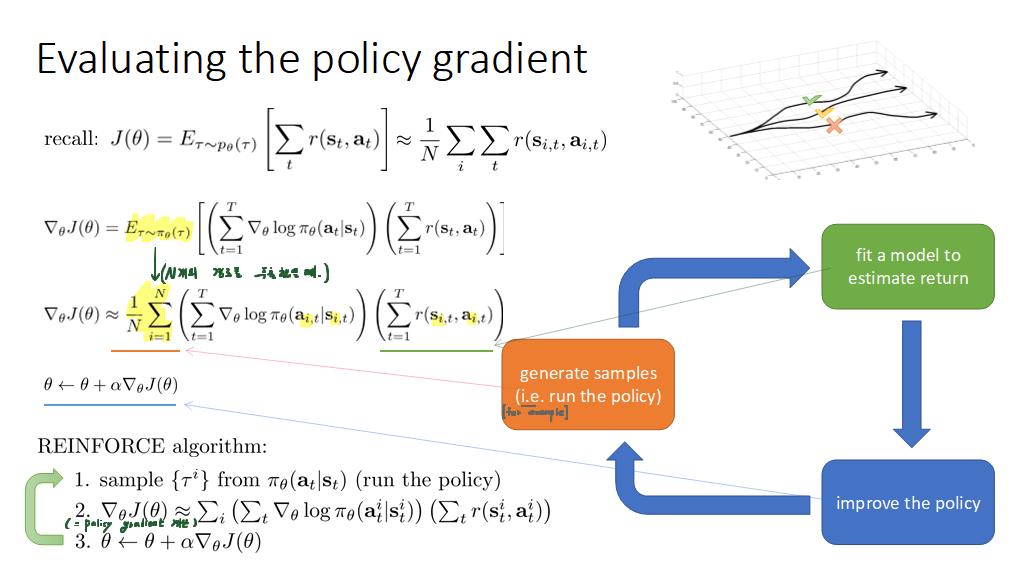
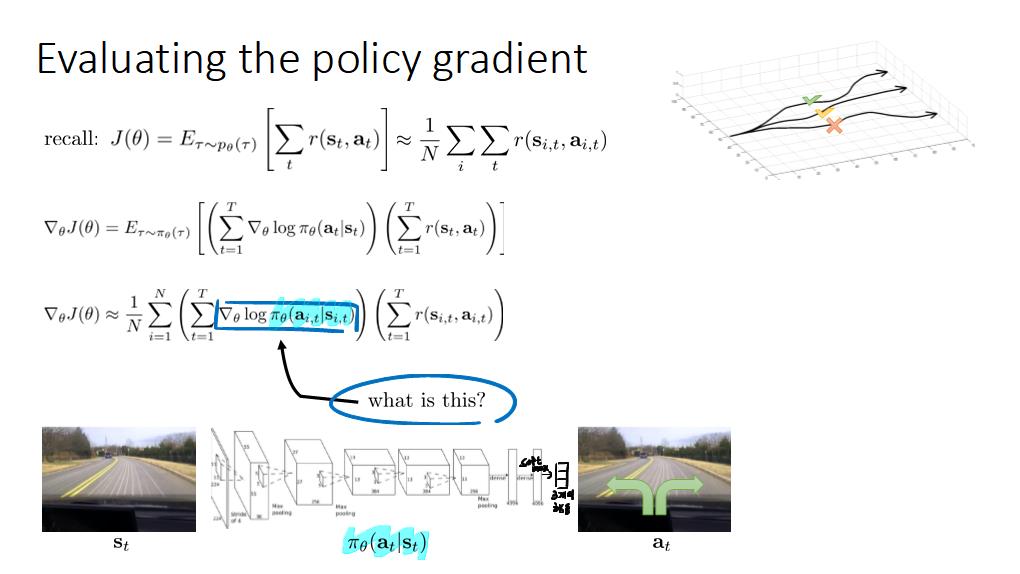
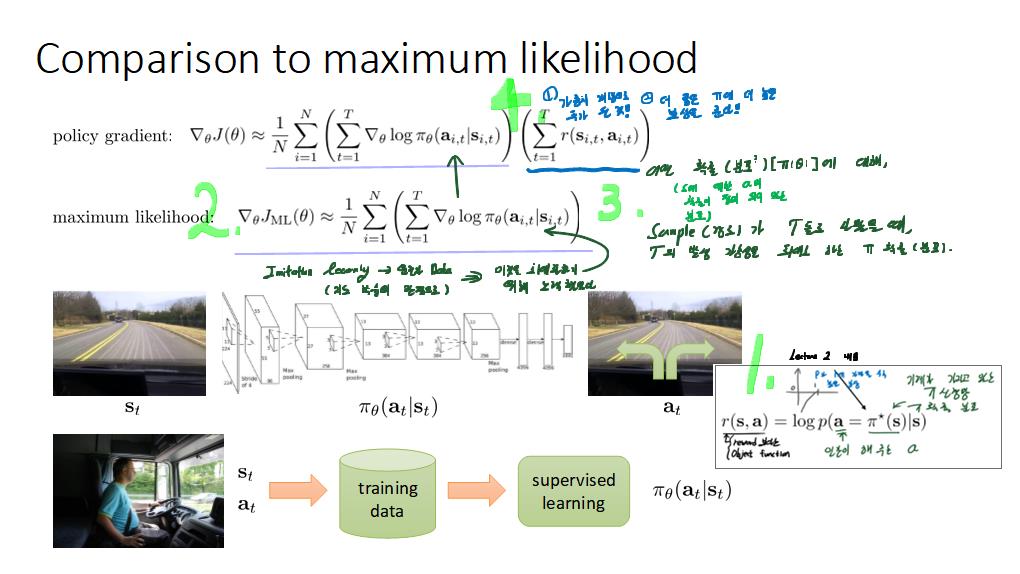
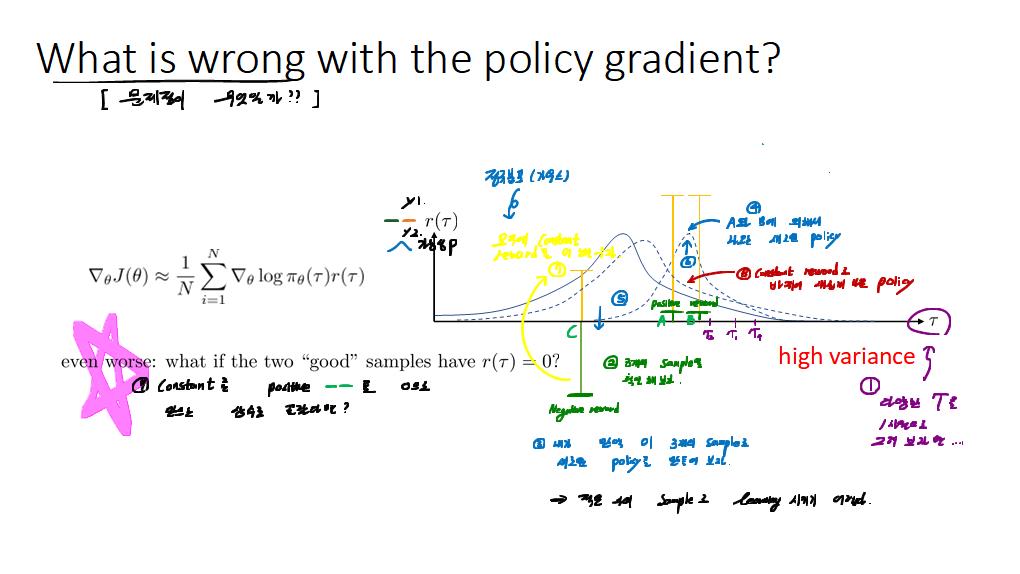
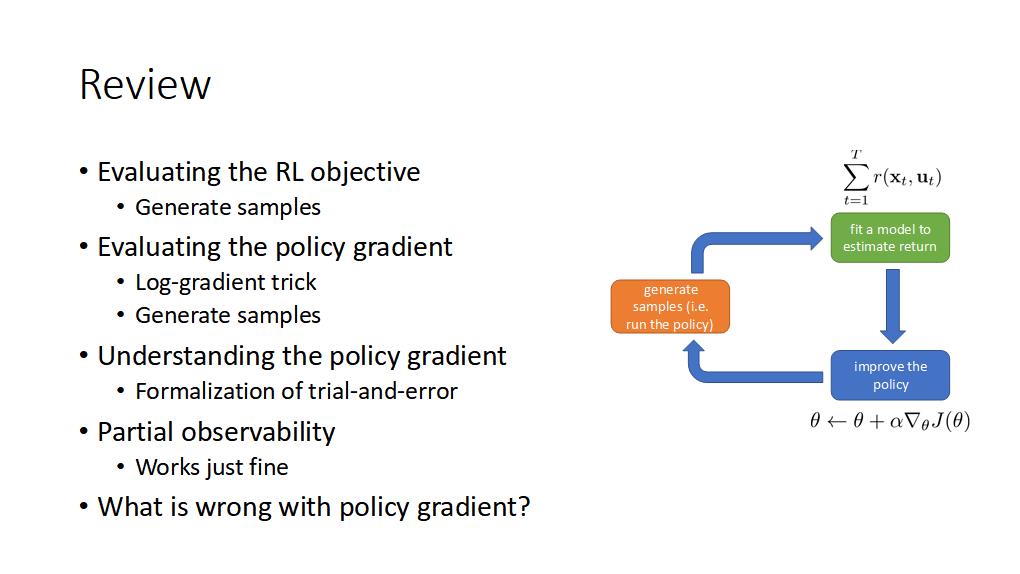
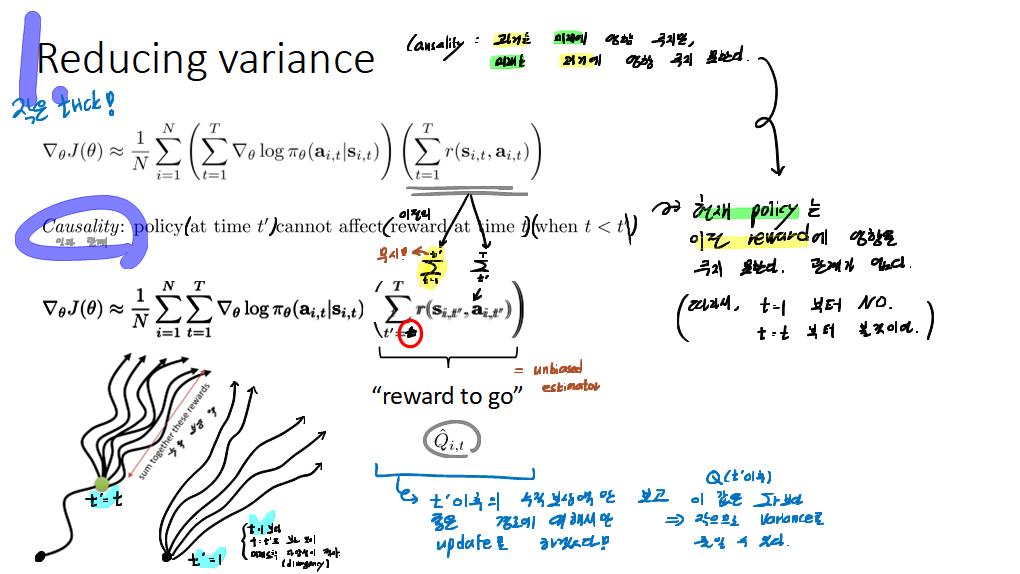
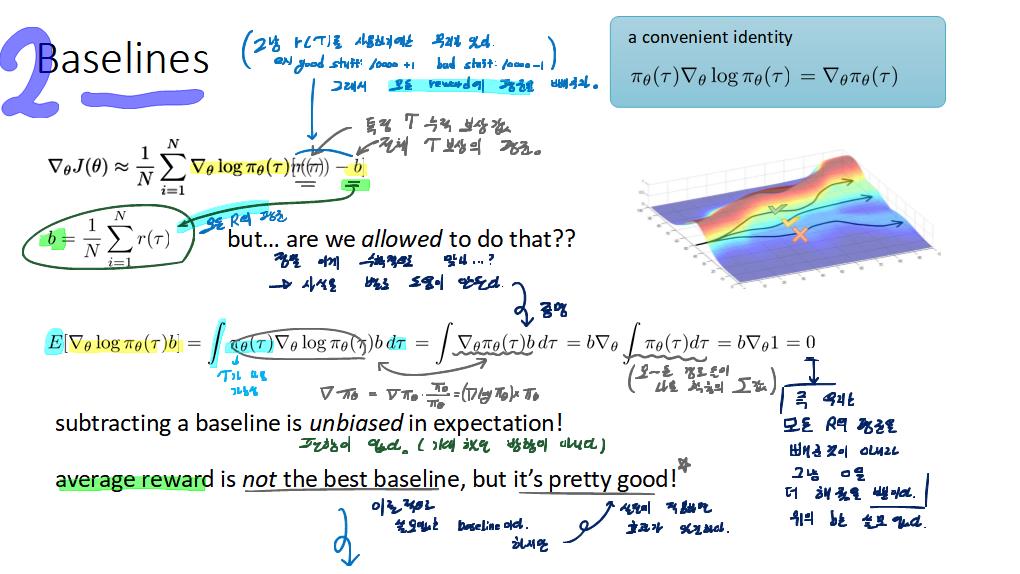
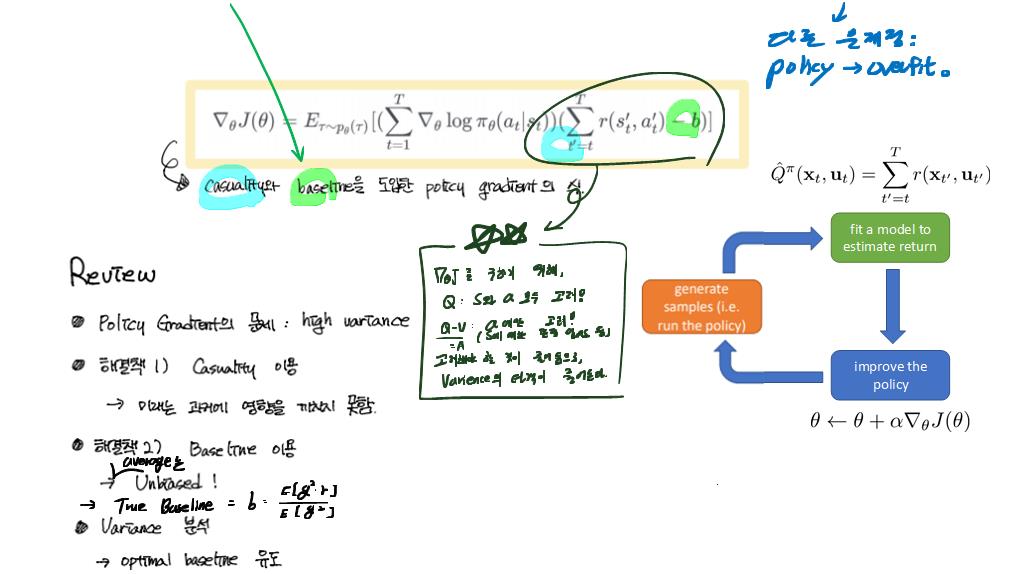
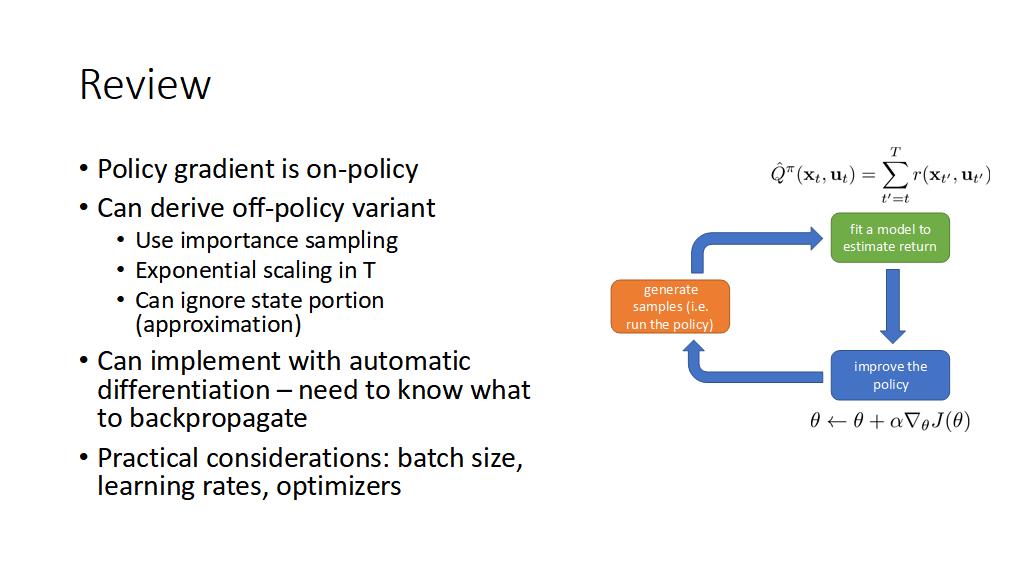
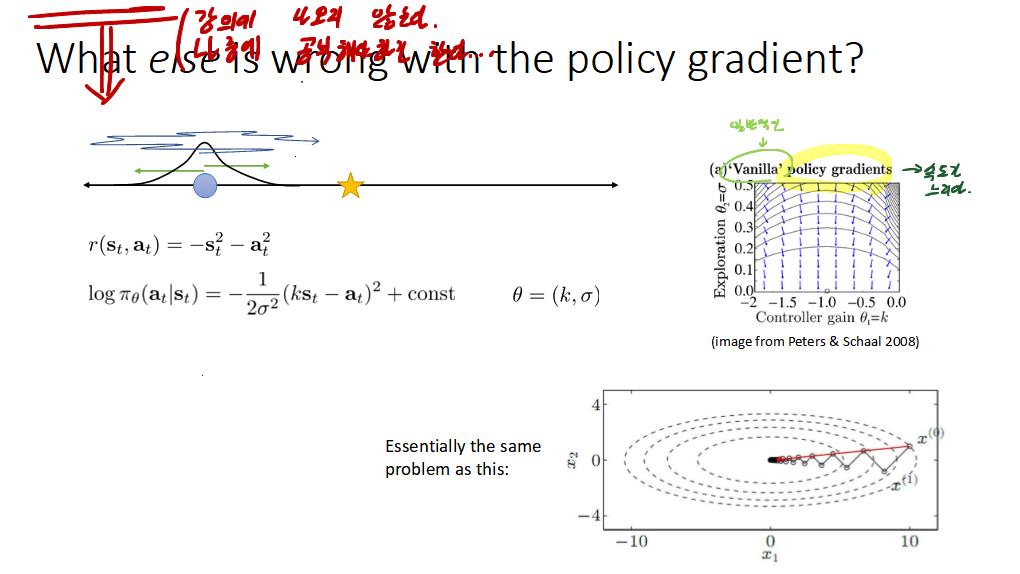
공부내용