Survey DG papers 정확히 과제를 해결하기 위해, **논문들을 읽으면서 고려해야할 사항**은 다음과 같다. **연구 세미나에서, 진짜 필요한 것은 큰그림을 잡고 토론하는 것! 논문 하나하나, 수식 하나하나, 메소드 하나하나가 아니다. 따라서 큰그림을 잡으려고 노력해보자. 큰 그림은 구체적으로 아래와 같은 것들이 있다.** 1. Top down 방식으로, DG에 정확하게 알아가자. 2. 기존 문제점에서, DG 논문들이 **해결하려고 하는 것**이 무엇인지? 3. DG의 **많은 방법론**들. 4. 그들의 **공통점과 차이점** 5. 최근 DG 논문들의 **최근 경향, 발전 방향** 6. 최근 DG논문들의 **문제점과 약점**이 무엇인지? **논문을 정리하면서 고려해야할 사항**은 다음과 같다. 1. 요약은 1논문당 15줄 이상을 넘어가지말자. 2. 핵심만 파악한다. 디테일한 요소는 중요하지 않다. 4. 꼭 이해할 필요는 없다. 어차피 그 내용으로 논문쓸것도 아닌데... **주의할 점** - **아이슈타인 "문제를 해결할 시간이 1시간 있고, 그 해결책에 내 인생이 달려있다면, 나는 우선 어떤 질문을 제기하는 게 적합한지 판단하는 데 55분을 쓸 것이다. 일단 적절한 질문을 알기만 한다면 문제 해결엔 5분도 걸리지 않을 것이기 때문이다."** - 썩지 말고, 문제점을 찾고 해결하자. "이렇게" 해보면 좋지 않을까? NO 기본에는 이것이 문제다. 이것을 "이렇게" 해결해보자! YES! **구체적인 목표 설정**을 위한 생각의 흐름 (페이 조언에 대한 생각) 1. 내가 생각하는 꿈과 최종 목표는 무엇인가? 최종적으로 완성된 기술은 무엇이 되기를 희망하는가? - 자율주행 자동차. 날씨, 도로, 지역, 시간 환경 변화에 따라서 **안전한** 검출 성능을 가지는 모델 개발에 이바지 하고 싶음. 2. 여러가지 Task (Classification, Object Detection, Sementic Segmentation) 중에서 왜 그것에 집중하는가? - Classification에 대한 연구는 이미 많이 이뤄져왔다. Domainbed에 따르면 그 어떤 방법도 그다지 Classification 성능향상에 도움이 되지 않는다. 왜냐? 이미 데이터가 충분하기 때문이다. Classification에서는 Domain 변화도 거스를만큼 이미 충분한 데이터가 존재한다. - 하지만 Driving을 위한 Detection, Segmentation Task에는 그렇지 않다. 모든 Domain을 고려할 만큼 충분한 Benchmark dataset이 존재하지 않는다. - Detection 성능을 올리는데 기여하고 싶지만, 연구를 위해 차근차근 다가가는 목적에서는 Segmentation Task에서의 성능향상이 먼저다. 그리고 Sementic Segmentation이 내가 가진 Resource에서의 한계 Task이다. 3. 어떤 Task를 해결하고 발전시킴으로써, 나의 최종목표에 다가가고 싶은가? - Domain Generalization, Domain Adaptation. - Recognition Task는 Benchmark dataset에 대한 SOTA 이외에 더 이상 의미는 없다. 진짜 Deep learning에서 해결해야하는 Task는 딥러닝 자체의 문제점 해결이다. 4. 그 Task를 해결하는 방법 중 main promising method 가 무엇이라고 생각하는가? - Style 정보를 Feature에서 제거하기? - Contrastive Learning Using many augmentation method ->> Network Appearnce/Style Invariance, Class cluster make bigger, - Test Time Learning? Domain Shifting? - Adaptive model - Style은 어쩔 수 없고, Network가 Content에 집중하게 만드는 방법은 뭘까? # 3.1 TTT: Tent-Fully Test-Time Adaptation by Entropy Minimization -ICLR21 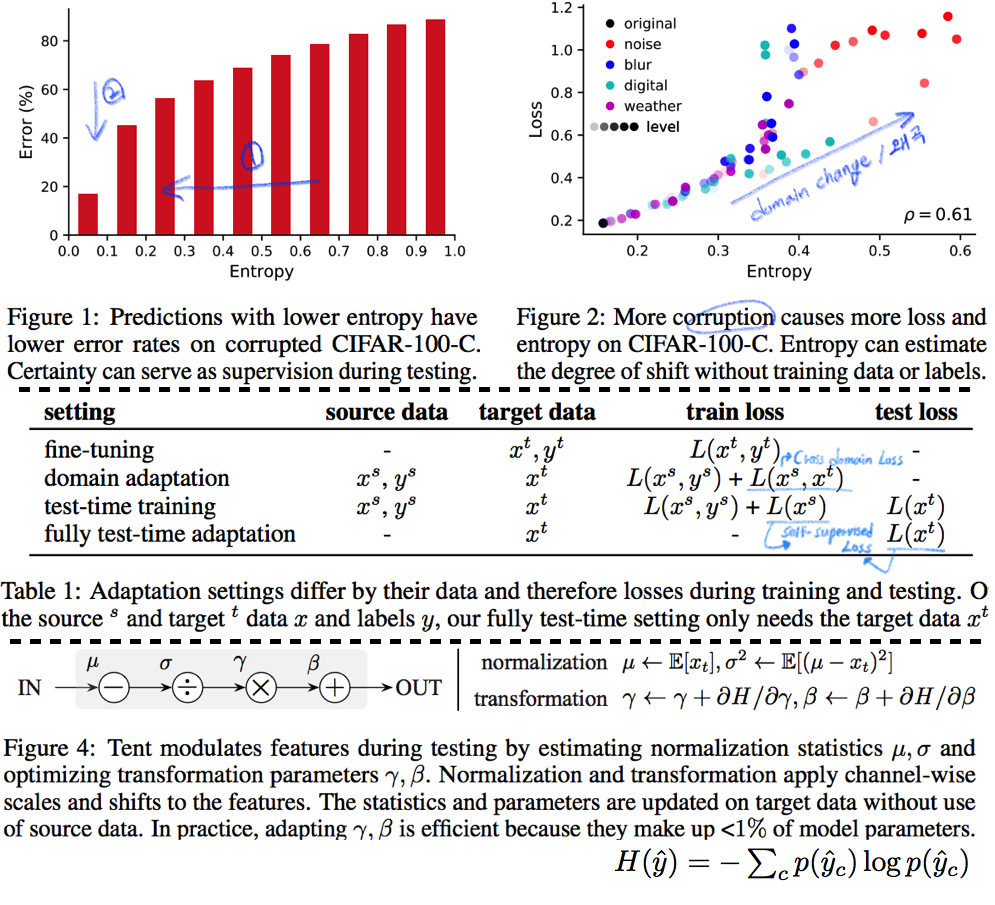 - Abstract - Entropy Confidence를 최적화하기 위해서, Norm statistics and channel-wise affine transformations 등을 추정하고 업데이트한다. - Source-free domain adpataion // fully test-time adaptation // practical adaptation - only one epoch of test-time optimization - Introduction - supervision on source data 에 너무 의지 하지 않아야 한다. - Availability, Efficiency (not reprocess source), Accuracy(batter than no adaptation) 를 가져야한다. - Entropy를 낮추면, 자연스럽게 Loss도 낮아질 것을 기대한다. - Method - Fully test-time adaptation으로써, Training Time 때 배우는 것들을 중 대부분은 그대로 놓는다. - High dimention 정보를 담고 있는 model weight를 바꾸는 행위는 모델에게 매우 불안정이고, 비효율적인 방법이다. - 따라서 Test Time 때 BN 파라미터만 학습한다. 이때 학습에 사용하는 Loss는 (ADVENT 논문의) Entropy probability 이다. # 3.2. TTT: Test-Time Training with Self-Supervision for Generalization under Distribution Shifts -arXiv19 - TTT 논문 - Training에서는 Equ(2) 와 같이 2가지 Loss를 사용해서 학습하고, Test에서는 Feature Extractor를 Self-supervised learning으로 Fine-turning한다. # 3.3. DG: Adaptive Methods for Real-World Domain Generalization -CVPR21  - 아주 적은 Unseen target domain data 만으로도 빠르게 적응할 수 있는, `adaptive classifier` 를 목표로 하는 DG - Introduction and Relative work 정리 1. domain invariant를 학습하기 위한 많은 노력이 있었으나, 아직 어떤 모델도 특정한 Test domain에서는 안정된 성능을 보장하지 못한다. 예를 들어 만약에 optimal universal classifier 를 찾았다고 하자. 하지만 Figure 1 처럼 새로운 Target domain과의 큰 adaptivity gap 을 가질 가능성은 여전히 있다. 따라서 우리는 어떤 Domain에서도 적응할 수 있는 adaptive classifier 개발을 목적으로 한다. 2. [7-2019] 논문에서 첫 주장된 kernel mean embeddings (KME) 방법을 사용하여, 아주 적은 unseen sample 만으로도 좋은 성능을 이끌어 낸다. - Approach - Domain Gap은 우리가 어떤 Source로 학습시키더라도 클 수 있다. - 따라서 우리의 목표는 어떤 Test Domain이 들어오더라도 그것에 적은 데이터로 빠르게 적응하는 Classifier를 만드는 것이다. - Domain Emdeding을 활용한 DG 1. kernel mean embeddings 기법을 활용해 각 Domain의 Mean 값을 계산한다. 즉, Domain에 어떤 이미지가 들어가도 그 Domain의 **Info/Style/Centroids**를 출력해주는 Network(Theta)를 개발한다. 이 Network는 Domain의 정보만을 뱉어줄 것이다 2. F_ft는 어떤 Domain이 들어와도, 안정적인 Feature Extact을 해주며, F_mlp에서는 Domain의 Centroid를 고려하여, Domain bias를 고려한 Classifier 역할을 한다. 3. Test time에는 아주 적은 unseen sample 만으로 Domain Prototype을 계산하고, F를 사용해서 Classification을 수행한다. - 추가적으로 (1) LSVRC12+YFCC100M을 기반으로 만든 Real-world domain generalization benchmark: `Geo-YFCC` 소개 (2) 위 방법의 Theoretical Guarantees를 논문에서 추가적으로 제시하므로 필요시 참고할 것. # 3.4. DG: Generalization on Unseen Domains via Inference-time Label-Preserving Target Projections -CVPR21 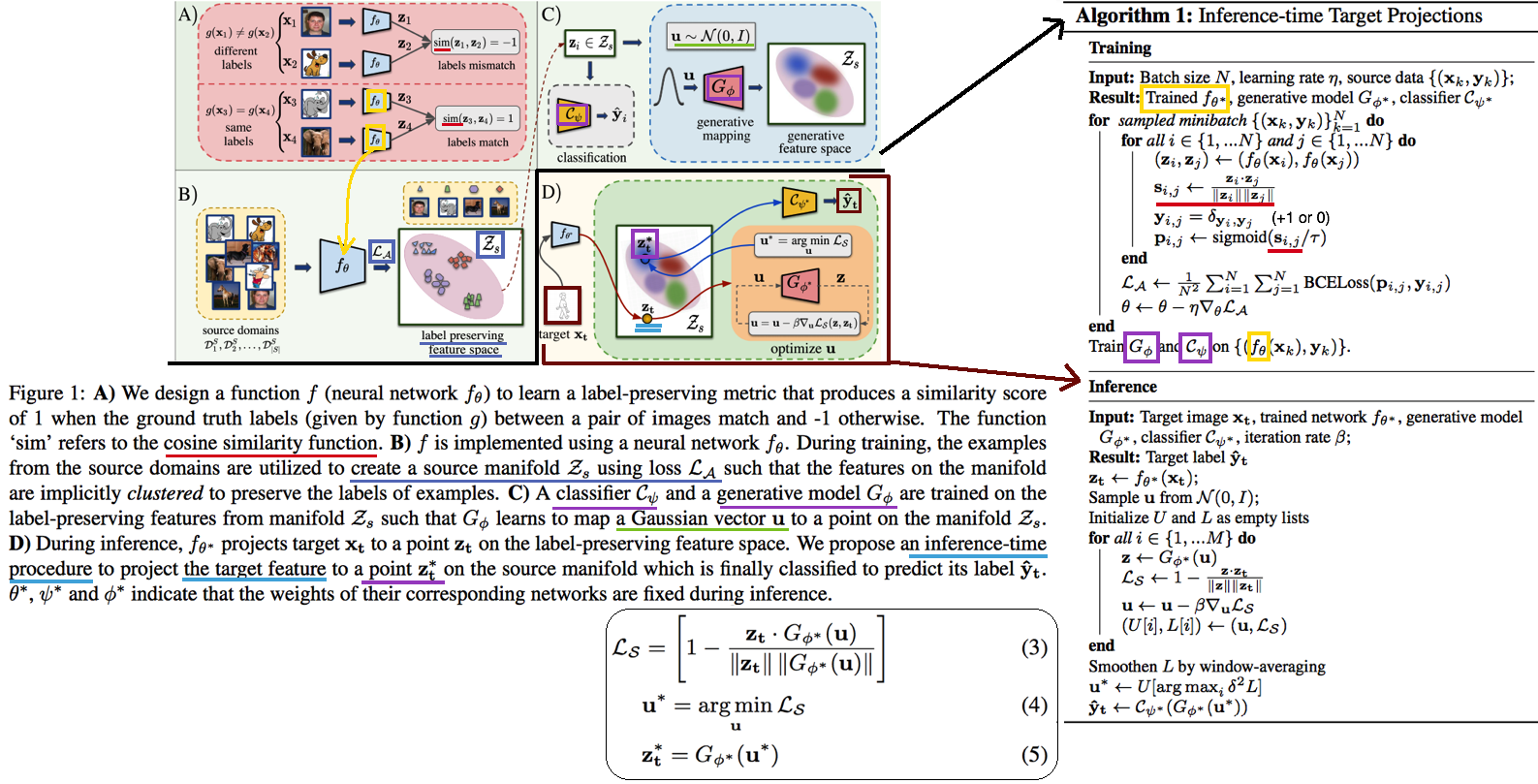 - classification을 잘 할 수 있는 `manifold space`로 feature를 던져버리는 DG // Image style transfer와 비슷한 느낌의 `Target feature projection` 이라고 표현된다. - Z_s라는 Space를 source data feature manifold라고 하자. classifier는 이 manifold 내부의 feature 만을 classification 잘 할 수 있다. 하지만 unseen target feature는 분명 manifold 내부에 잊지 않을 가능성이 크다. 따라서 target feature를 manifold 내부로 던져 (push) 버리는 G network를 학습하여 사용한다. - Introduction and Relative work 정리 1. 지금까지 DG들은 Source data 만을 사용한다. 하지만 test시에 target example을 1개라도 쓸 수 있다는 점을 무시한다. 그러니 Target과 source와의 gap이 생기는 것은 당연하다. "이러한 상황" 속에서 inference과정 중 target을 효율적이고/적절히 사용하는 방법에 대해서 제안한다. (G 모듈이 추가한 것에 대한 변명인가?) "이러한 상황"이 비판적이라고 말할 수 있지만, 인간에게는 당연한 상황이다. 인간은 unseen object를 만나더라도 감각적으로 similar object를 잘 관련시키는 능력을 가지고 있기 때문에, DG setting도 non-practical 하다고 비판만 하는 것은 문제가 있다. 2. 기존의 DG 방법에는 adversarial learning/ meta learning/ Augmenting the source dataset(:= Style Transfer/ GAN을 통한 Target 같은 data 생성)/ Domain-invariant representations(MMD, CORAL)/ Data augmentaiton (:= Color jittering/ Target domain을 시뮬레이션 한다. 하지만 한계가 존재한다.)/ Self-supervised Learning(jigsaw puzzle) 3. [27], [16], [45] 논문은 이 논문에서 추천하는 위의 방법과는 다른 DG이다. 이것들 보단 우선 최신 논문을 더 읽어, 최신 흐름을 파악하자. - 좀더 자세한 Method는 아래와 같다. (학습과정을 포함한 몇가지가 완전히 이해가지는 않는다. 필요하면 더 찾아보고, 코드를 보자.) - G network는 2가지 형태가 될 수 있다. 논문 결과에서는 VAE 방식에서 더 좋은 성능이 나왔다고 한다. 1. VAE방식: Encoder는 z_i가 들어가서 u~N(0,1)의 Noise가 나와야 하고, Decoders는 Z_i를 reconstruction하면 된다. 2. GAN방식: U가 들어가면 Z_i가 출력되도록 generator를 학습시킨다. (이것은 z_i 정보를 사용하지 않으니, 당연히 성능이 안나오는게 정상 아닐까?) - z\*t 는 z_t 와 cosine distance(코사인 유사도)가 최대한 가까운 (Equ(5)) vector를 generate할 수 있는 u를 찾고, u를 G에 통과시켜 z\*_t 를 생성한다.(= z_t가 z\*t로 push 되었다!) z\*t는 Generator를 통해서 나온 것이기 때문에 manifold 내부에 있을 것이 보장된다고 한다. - Analysis and Implementation 부분에서, z\*_t 을 사용하는 것이 왜 합당한지, 수학적으로 간단히 증명해놓았다. 필요하면 참고하자. # 3.5. Generalizable Semantic Segmentation via Model-agnostic Learning and Target-specific Normalization -arXiv20 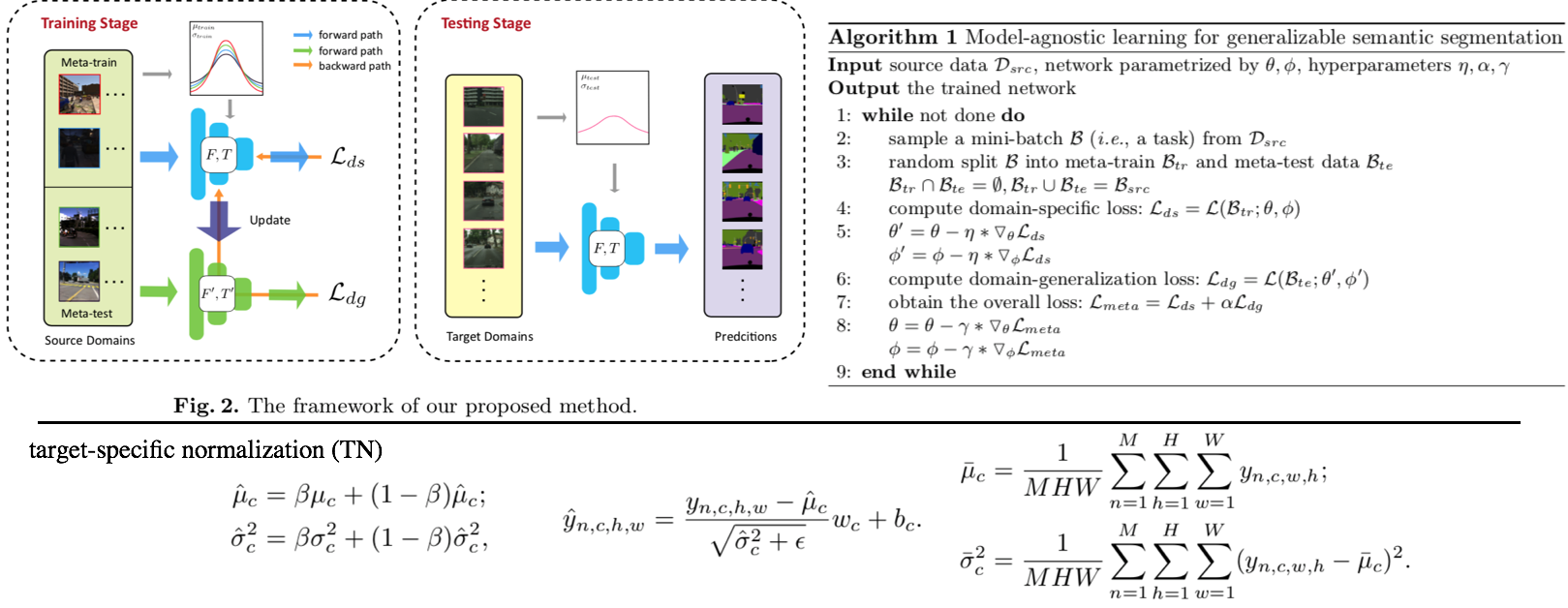 - Meta-learning을 활용하는 DG - Method는 과거의 MAML, MLDG 방법을 Segmentaion 에 적용한게 전부이다. - 추가적인 방법이 Target-specific normalization 방법인데, normalization에서 사용하는 mean과 std를 그대로 사용하지 않고 moving average 기법을 사용해 normalization하겠다는 방법이다. 이 과정을 통해서 unseen의 normalization을 mimic할 수 있다고 주장한다. (개인적인 생각으로 Generalization 성능의 작은 향상은 줄 수 있겠지만, 큰 도움은 안 될 듯하다.) - 성능은 AdaptSeg-Net 수준이긴 이고, RobustNet보다는 GTAV->Cityscape 성능은 좋다고 나와 있다. 하지만 실험이 워낙 적고 그렇게 신뢰할만한 실험 결과들을 다수로 제시하지 않았다. 따라서 필요하면 참고하고, 나중에 굳이 성능 비교 논문으로 사용하지 말자. # 3.6. DG: Reducing Domain Gap by Reducing Style Bias -CVPR21  - Style removing(Image에서 Style 정보를 제거한 Feature 변환 or 추출을 목적으로 함)과는 비슷하지만 다르다. CNN이 `Style`에 집중하지 않고 `content`에 집중하도록 유도하는 DG - Introduction and Relative work 정리 1. CNN의 가장 큰 문제점: CNNs’ strong **inductive bias** towards image styles. 따라서 Style-Agnostic Networks (SagNets)를 사용해서 class categories에서 style encodings을 분리한다 2. 인간의 Vision은 객체의 Only Contents를 보고 판단을 한다. (한장의 객체 사진으로 Real world, 만화, 그림 등의 객체를 모두 동일한 것으로 판단할 수 있다.) 하지만 CNN은 Content만을 보고 판단하지 않는다. Style, Texture 또한 많이 보고 판단한다. 이 사실을 정확히 증명하고 분석한 논문이 아래의 \[#3.7\] 이다. 따라서 현재의 CNN은 Style에 민감하고 Domain의 변화에 민감할 수 밖에 없다. 3. 따라서 본 논문은 이러한 문제를 해결하기 위해 모델을 개발하였으며, 특히 multiple domains 을 사용하지 않고 `Intrinsic bias` 를 제거하려고 노력하였다. 4. 이 논문의 Method는 기존 Adversarial Learning 기법들과는 조금 다르다. 확실한 Discriminator가 없고, Classifier(G_s)가 Discriminator와 비슷한 역할을 하게 만들고, Adversarial Learning은 G_s가 판단을 헷갈리게 하는 방식으로 진행한다. - 핵심 Method 설명 1. Content-Biased Learning: G_c (Centent Classifier) 를 학습하기 위해, Style randomization 수행 2. Adversarial Style biased Learning: G_f (Feature Extractor) 를 학습하기. G_s를 통과하고 나온 vector가 1/K x ones(K) 이되도록, G_f가 학습된다. 구체적으로, G_f의 Feature map이 Label에 대한 정보를 Feature의 Mean, Std에 담지 못하게 유도함으로써, G_s (discriminator) 가 Classification을 잘하지 못하도록 만든다. 3. 만약 UDA 세팅으로 하고 싶다면, x는 target dataset(unlabled)의 이미지이다. Style Randomization을 하든 안하든, Classifier를 통과하고 나온 Feature는 유사해야한다는 사실을 이용한다. ## 3.6.1. A style-based recalibration module for convolutional neural networks -ICCV19 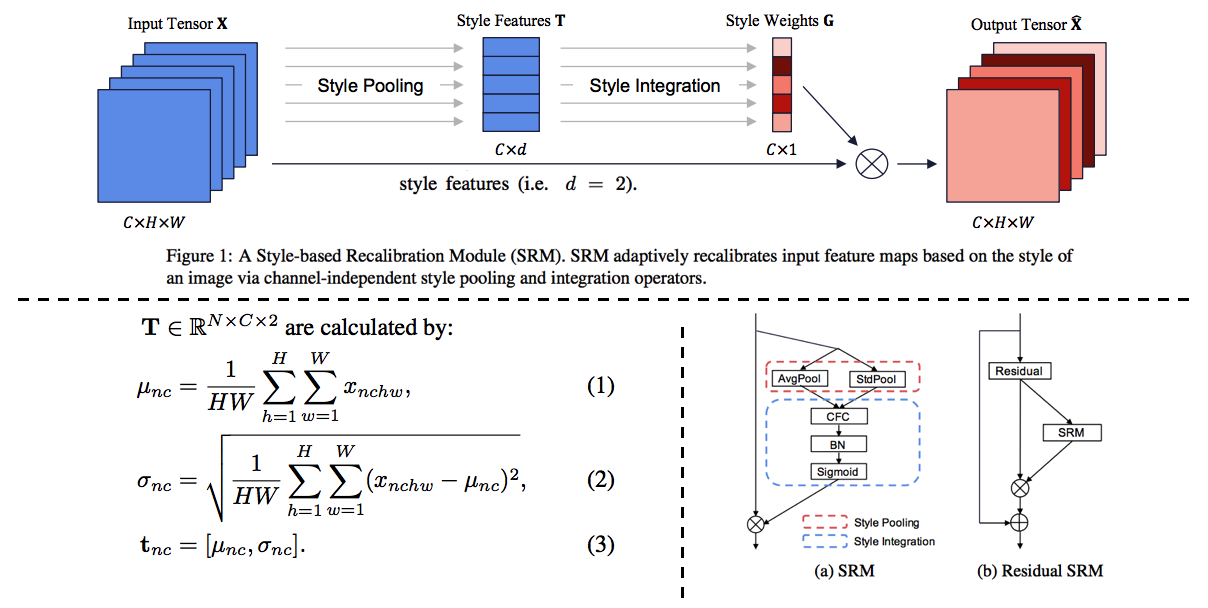 - CBAM과 같은 목적의 논문. Style에 좀 더 집중한 Style-based Recalibration Module (SRM) - 본래 이미지의 Style정보를 활용해서 Feature에 Style 혹은 Contencts Attention 효과를 얻어, `the representational ability of a CNN` 을 향상시키고자 한다. - Recognition 혹은 Style Transfer로 Feature representation 성능을 확인한다. # 3.7. DG: ImageNet-trained CNNs are biased towards texture -ICLR19 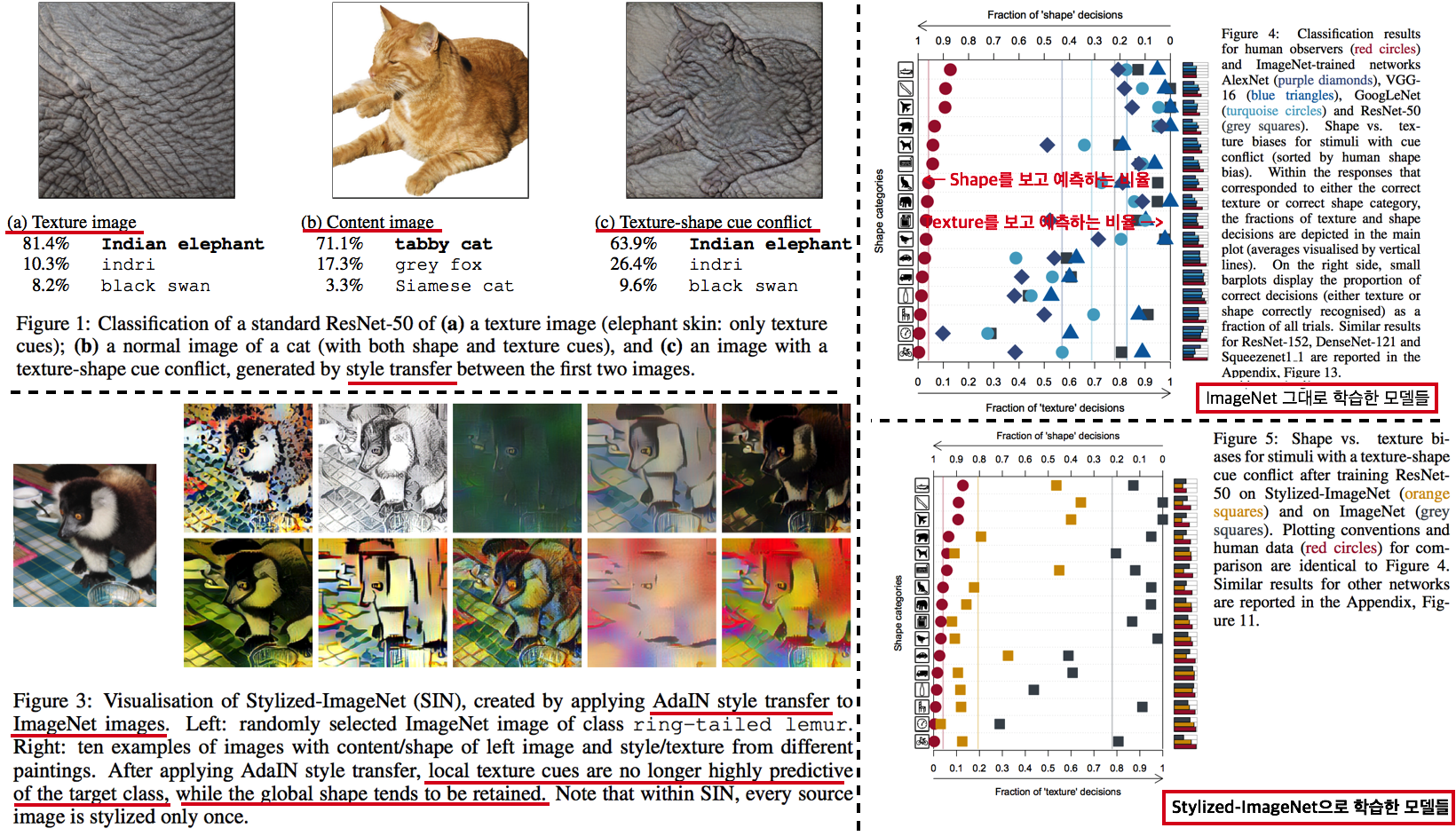 - (Citation 미친 논문) 사실 DG는 아니고, ImageNet으로 학습시킨 모델들의 문제점을 확실히 파악하고, `New Stylized Dataset` 을 사용하면 이 문제점을 완화할 수 있다고 말하는 논문이다. - ImageNet을 가지고 학습시킨 CNN이 Shpae/Contenct가 아닌 Strong Texture/Style Bias를 가지는 것을 확인했다. - 자신들이 새롭게 만든 Dataset인 `Stylized ImageNet`을 통해서, Texture/Style가 아닌 Shpae/Contenct를 집중해서 학습하도록 만들 수 있다. # 3.8. DG: Domain Generalization with MixStyle -ICLR21  - AdaIN 개념의 γ (감마) and β (배타) 값을 Random/Mixing 해서 줌으로써 Style-Invariance를 주는 DG - Source domains 간의 `mixing instance level feature statistics ` 를 수행함으로써 DG성능을 올린다. - Introduction and Relative work 정리 1. DG를 성취하는 가장 단순한 방법은, 아주 많은 source domains을 가지고 Dataset을 학습하는 것이다. 이러한 방법은 상업적으로 얼굴인식이나 자율주행 분야에서 큰 효과(성공)을 가져왔다. - Key Sentence 1. Mixing styles of training instances results in novel domains being synthesized implicitly, which increase the domain diversity of the source domains, and hence the generalizability. 2. MixStyle fits into mini-batch training perfectly and is extremely easy to implement. # 3.9. Deep Domain Generalization via Conditional Invariant Adversarial Networks -ECCV18 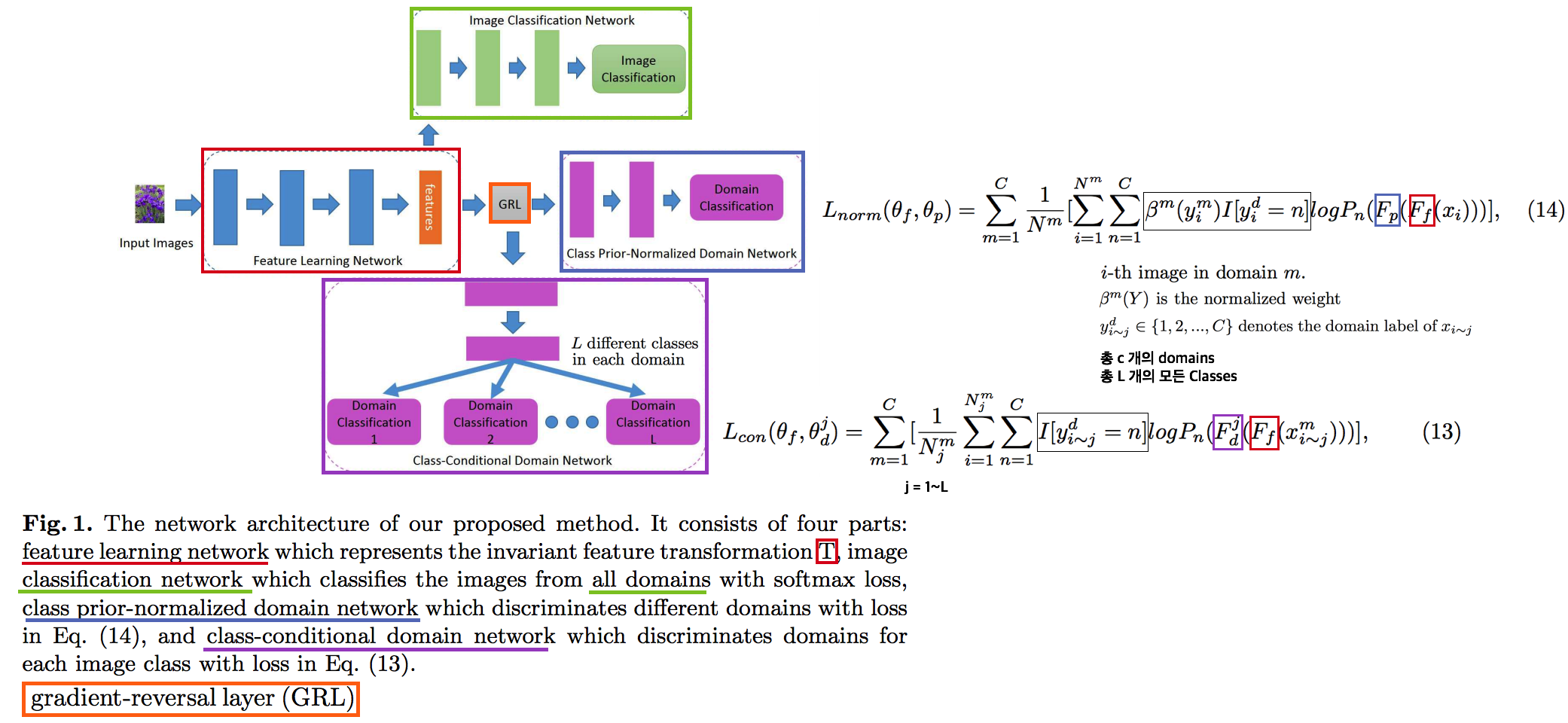 - `Conditional invariant adversarial network` 를 활용한 DG - 이 논문이 유명한 이유는 Gradient-reversal Layer를 사용하는게 왜 DG에 도움이 되는지 수학 수식으로 구체적으로 증명해놓았기 때문이다. (증명은 굳이 이해하지 않았다) 따라서 Method 및 실험결과 자체만 보면 별거 없다는 생각이 들수도 있다. - 기존의 GRL 논문과 다른 것은 Class-wise Adversarial Nework를 사용했다는 것이 전부이다. # 3.10. Deep domain-adversarial image generation for domain generalisation -AAAI20 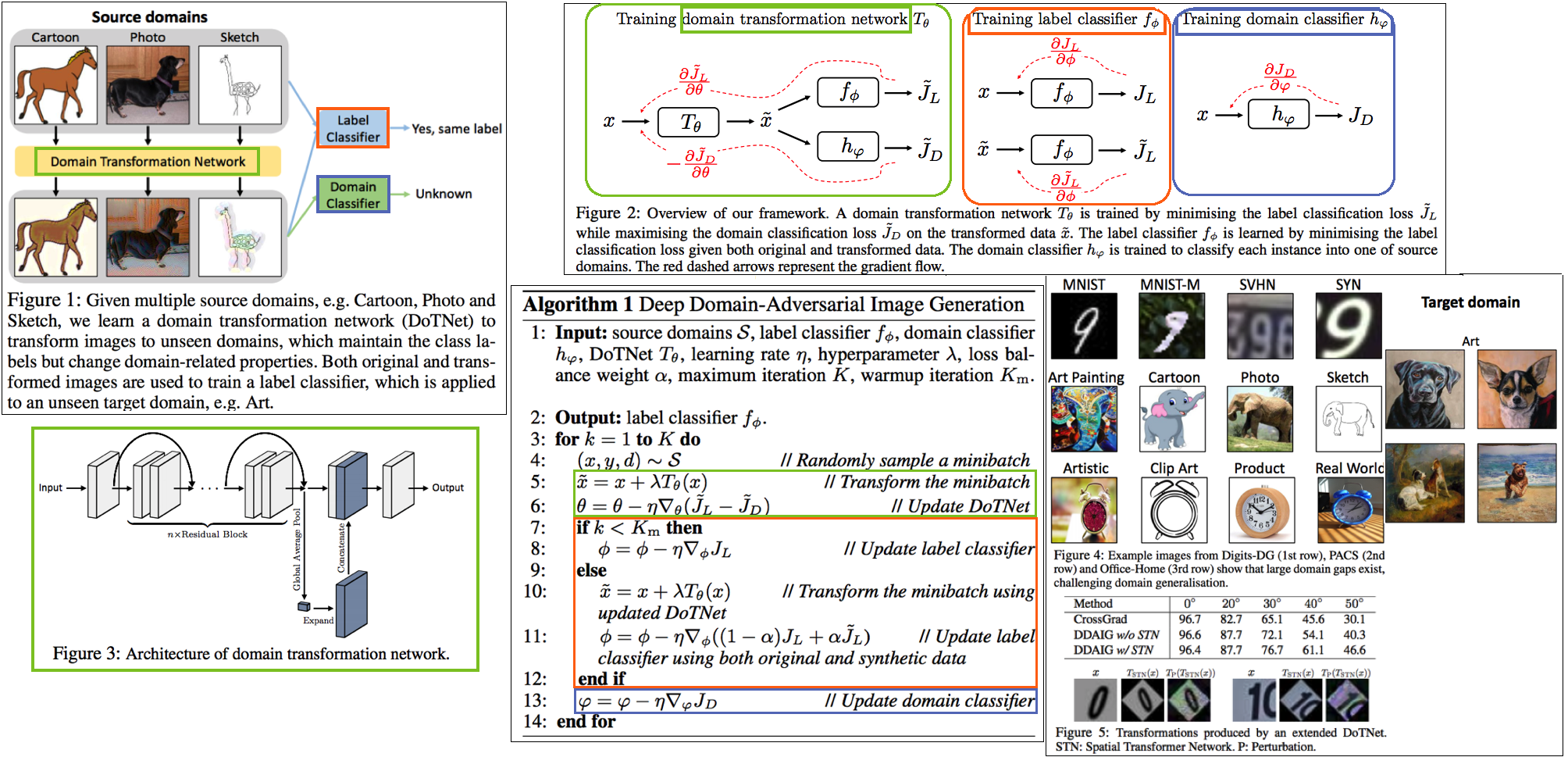 - 새로운 Style의 Image를 만들기 위해서, Domain Transformation Network (=New Style Generating Network) 를 활용하는 DG - 중간 초록색 상자를 주목하면 되는데, (Style Transfer Network) T는 \[ **(1)** Label Classificaton 이 잘되게 하는 이미지 **(2)** 어떤 Domain 인지 Domain classifier가 예측하지 못할만한 이미지를 Reconstruction 하도록 학습된다. # 3.11. In Search of Lost Domain Generalization - ICLR21 - Github: (1) [https://github.com/facebookresearch/DomainBed](https://github.com/facebookresearch/DomainBed), (2) [ERM code](https://github.com/facebookresearch/DomainBed/blob/master/domainbed/algorithms.py#L70) , (3) [Algorithms](https://github.com/facebookresearch/DomainBed/blob/master/domainbed/algorithms.py) - 공정한 DG 성능 평가를 위해서 datasets, network architectures, and model selection criteria 통일 방안을 제시한 논문 ` How useful are different DG algorithms when evaluated in a consistent and realistic setting?` - Abstract - `DOMAINBED` 를 통해서, 7개의 Benchmarks, 14개의 알고리즘, 3개의 model selection 기준을 제시한다. - SOTA는 여전히 ERM (Empirical risk minimization) 이다. - 자율주행 장애물 요소: Light, weather, object pose - Biase 이유: Texture statistics, object backgrounds, racial biases - 많은 실험을 통해서 깨달은 takeaways 1. average performance 관점에서는 Carefully tuned ERM 가 SOTA 이다. - ResNet50이 ResNet18 보다 당연히 DG에 좋다. 하지만 기존 알고리즘은 ResNet18을 사용하곤 했다. - 따라서 ResNet50을 사용하고, 하이퍼파라메터를 적절히 튜닝한 ERM 모델이 더 좋은 성능을 가져와 주었다. 2. 14가지 DG 알고리즘 중 ERM 보다 1점 이상 높은 성능을 가지는 것은 없었다. - 새로운 알고리즘이 DG에 좋을 수는 있지만.. 엄격한 방식으로 평가하다면 ERM 보다 높은 DG 성능을 얻은 것은 상당히 challenging 할 것이다. - 대부분의 DG 알고리즘들은 ERM-like performance 을 가졌다. - Our advice to DG practitioners is to use ERM (which is a safe contender) or CORAL (Sun and Saenko, 2016) (which achieved the highest average score) 3. DG에서 Model Selection은 매우 중요하다. 따라서 DG 알고리즘들은 자신의 모델 선택 기준 (model selection criteria) 을 명시해야한다. - (예를 들어서 choosing hyperparameters, training checkpoints, architecture variants 구체적인 것은 논문 추가 참조) - 이렇게 되어 있는데, 이해가 안된다. We observe that model selection with a training domain validation set outperforms leave-one-domain-out cross-validation across multiple datasets and algorithms. This does not mean that using a training domain validation set is the right way to tune hyperparameters. In fact, the stronger performance of oracle-selection (+2.3 points for ERM) suggests headroom to develop improved DG model selection criteria.
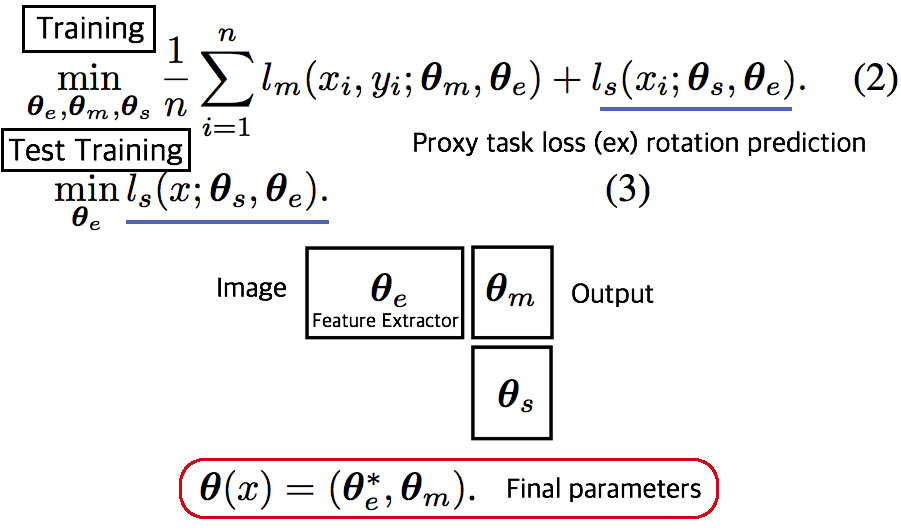 - TTT 논문 - Training에서는 Equ(2) 와 같이 2가지 Loss를 사용해서 학습하고, Test에서는 Feature Extractor를 Self-supervised learning으로 Fine-turning한다. # 3.3. DG: Adaptive Methods for Real-World Domain Generalization -CVPR21  - 아주 적은 Unseen target domain data 만으로도 빠르게 적응할 수 있는, `adaptive classifier` 를 목표로 하는 DG - Introduction and Relative work 정리 1. domain invariant를 학습하기 위한 많은 노력이 있었으나, 아직 어떤 모델도 특정한 Test domain에서는 안정된 성능을 보장하지 못한다. 예를 들어 만약에 optimal universal classifier 를 찾았다고 하자. 하지만 Figure 1 처럼 새로운 Target domain과의 큰 adaptivity gap 을 가질 가능성은 여전히 있다. 따라서 우리는 어떤 Domain에서도 적응할 수 있는 adaptive classifier 개발을 목적으로 한다. 2. [7-2019] 논문에서 첫 주장된 kernel mean embeddings (KME) 방법을 사용하여, 아주 적은 unseen sample 만으로도 좋은 성능을 이끌어 낸다. - Approach - Domain Gap은 우리가 어떤 Source로 학습시키더라도 클 수 있다. - 따라서 우리의 목표는 어떤 Test Domain이 들어오더라도 그것에 적은 데이터로 빠르게 적응하는 Classifier를 만드는 것이다. - Domain Emdeding을 활용한 DG 1. kernel mean embeddings 기법을 활용해 각 Domain의 Mean 값을 계산한다. 즉, Domain에 어떤 이미지가 들어가도 그 Domain의 **Info/Style/Centroids**를 출력해주는 Network(Theta)를 개발한다. 이 Network는 Domain의 정보만을 뱉어줄 것이다 2. F_ft는 어떤 Domain이 들어와도, 안정적인 Feature Extact을 해주며, F_mlp에서는 Domain의 Centroid를 고려하여, Domain bias를 고려한 Classifier 역할을 한다. 3. Test time에는 아주 적은 unseen sample 만으로 Domain Prototype을 계산하고, F를 사용해서 Classification을 수행한다. - 추가적으로 (1) LSVRC12+YFCC100M을 기반으로 만든 Real-world domain generalization benchmark: `Geo-YFCC` 소개 (2) 위 방법의 Theoretical Guarantees를 논문에서 추가적으로 제시하므로 필요시 참고할 것. # 3.4. DG: Generalization on Unseen Domains via Inference-time Label-Preserving Target Projections -CVPR21  - classification을 잘 할 수 있는 `manifold space`로 feature를 던져버리는 DG // Image style transfer와 비슷한 느낌의 `Target feature projection` 이라고 표현된다. - Z_s라는 Space를 source data feature manifold라고 하자. classifier는 이 manifold 내부의 feature 만을 classification 잘 할 수 있다. 하지만 unseen target feature는 분명 manifold 내부에 잊지 않을 가능성이 크다. 따라서 target feature를 manifold 내부로 던져 (push) 버리는 G network를 학습하여 사용한다. - Introduction and Relative work 정리 1. 지금까지 DG들은 Source data 만을 사용한다. 하지만 test시에 target example을 1개라도 쓸 수 있다는 점을 무시한다. 그러니 Target과 source와의 gap이 생기는 것은 당연하다. "이러한 상황" 속에서 inference과정 중 target을 효율적이고/적절히 사용하는 방법에 대해서 제안한다. (G 모듈이 추가한 것에 대한 변명인가?) "이러한 상황"이 비판적이라고 말할 수 있지만, 인간에게는 당연한 상황이다. 인간은 unseen object를 만나더라도 감각적으로 similar object를 잘 관련시키는 능력을 가지고 있기 때문에, DG setting도 non-practical 하다고 비판만 하는 것은 문제가 있다. 2. 기존의 DG 방법에는 adversarial learning/ meta learning/ Augmenting the source dataset(:= Style Transfer/ GAN을 통한 Target 같은 data 생성)/ Domain-invariant representations(MMD, CORAL)/ Data augmentaiton (:= Color jittering/ Target domain을 시뮬레이션 한다. 하지만 한계가 존재한다.)/ Self-supervised Learning(jigsaw puzzle) 3. [27], [16], [45] 논문은 이 논문에서 추천하는 위의 방법과는 다른 DG이다. 이것들 보단 우선 최신 논문을 더 읽어, 최신 흐름을 파악하자. - 좀더 자세한 Method는 아래와 같다. (학습과정을 포함한 몇가지가 완전히 이해가지는 않는다. 필요하면 더 찾아보고, 코드를 보자.) - G network는 2가지 형태가 될 수 있다. 논문 결과에서는 VAE 방식에서 더 좋은 성능이 나왔다고 한다. 1. VAE방식: Encoder는 z_i가 들어가서 u~N(0,1)의 Noise가 나와야 하고, Decoders는 Z_i를 reconstruction하면 된다. 2. GAN방식: U가 들어가면 Z_i가 출력되도록 generator를 학습시킨다. (이것은 z_i 정보를 사용하지 않으니, 당연히 성능이 안나오는게 정상 아닐까?) - z\*t 는 z_t 와 cosine distance(코사인 유사도)가 최대한 가까운 (Equ(5)) vector를 generate할 수 있는 u를 찾고, u를 G에 통과시켜 z\*_t 를 생성한다.(= z_t가 z\*t로 push 되었다!) z\*t는 Generator를 통해서 나온 것이기 때문에 manifold 내부에 있을 것이 보장된다고 한다. - Analysis and Implementation 부분에서, z\*_t 을 사용하는 것이 왜 합당한지, 수학적으로 간단히 증명해놓았다. 필요하면 참고하자. # 3.5. Generalizable Semantic Segmentation via Model-agnostic Learning and Target-specific Normalization -arXiv20  - Meta-learning을 활용하는 DG - Method는 과거의 MAML, MLDG 방법을 Segmentaion 에 적용한게 전부이다. - 추가적인 방법이 Target-specific normalization 방법인데, normalization에서 사용하는 mean과 std를 그대로 사용하지 않고 moving average 기법을 사용해 normalization하겠다는 방법이다. 이 과정을 통해서 unseen의 normalization을 mimic할 수 있다고 주장한다. (개인적인 생각으로 Generalization 성능의 작은 향상은 줄 수 있겠지만, 큰 도움은 안 될 듯하다.) - 성능은 AdaptSeg-Net 수준이긴 이고, RobustNet보다는 GTAV->Cityscape 성능은 좋다고 나와 있다. 하지만 실험이 워낙 적고 그렇게 신뢰할만한 실험 결과들을 다수로 제시하지 않았다. 따라서 필요하면 참고하고, 나중에 굳이 성능 비교 논문으로 사용하지 말자. # 3.6. DG: Reducing Domain Gap by Reducing Style Bias -CVPR21  - Style removing(Image에서 Style 정보를 제거한 Feature 변환 or 추출을 목적으로 함)과는 비슷하지만 다르다. CNN이 `Style`에 집중하지 않고 `content`에 집중하도록 유도하는 DG - Introduction and Relative work 정리 1. CNN의 가장 큰 문제점: CNNs’ strong **inductive bias** towards image styles. 따라서 Style-Agnostic Networks (SagNets)를 사용해서 class categories에서 style encodings을 분리한다 2. 인간의 Vision은 객체의 Only Contents를 보고 판단을 한다. (한장의 객체 사진으로 Real world, 만화, 그림 등의 객체를 모두 동일한 것으로 판단할 수 있다.) 하지만 CNN은 Content만을 보고 판단하지 않는다. Style, Texture 또한 많이 보고 판단한다. 이 사실을 정확히 증명하고 분석한 논문이 아래의 \[#3.7\] 이다. 따라서 현재의 CNN은 Style에 민감하고 Domain의 변화에 민감할 수 밖에 없다. 3. 따라서 본 논문은 이러한 문제를 해결하기 위해 모델을 개발하였으며, 특히 multiple domains 을 사용하지 않고 `Intrinsic bias` 를 제거하려고 노력하였다. 4. 이 논문의 Method는 기존 Adversarial Learning 기법들과는 조금 다르다. 확실한 Discriminator가 없고, Classifier(G_s)가 Discriminator와 비슷한 역할을 하게 만들고, Adversarial Learning은 G_s가 판단을 헷갈리게 하는 방식으로 진행한다. - 핵심 Method 설명 1. Content-Biased Learning: G_c (Centent Classifier) 를 학습하기 위해, Style randomization 수행 2. Adversarial Style biased Learning: G_f (Feature Extractor) 를 학습하기. G_s를 통과하고 나온 vector가 1/K x ones(K) 이되도록, G_f가 학습된다. 구체적으로, G_f의 Feature map이 Label에 대한 정보를 Feature의 Mean, Std에 담지 못하게 유도함으로써, G_s (discriminator) 가 Classification을 잘하지 못하도록 만든다. 3. 만약 UDA 세팅으로 하고 싶다면, x는 target dataset(unlabled)의 이미지이다. Style Randomization을 하든 안하든, Classifier를 통과하고 나온 Feature는 유사해야한다는 사실을 이용한다. ## 3.6.1. A style-based recalibration module for convolutional neural networks -ICCV19  - CBAM과 같은 목적의 논문. Style에 좀 더 집중한 Style-based Recalibration Module (SRM) - 본래 이미지의 Style정보를 활용해서 Feature에 Style 혹은 Contencts Attention 효과를 얻어, `the representational ability of a CNN` 을 향상시키고자 한다. - Recognition 혹은 Style Transfer로 Feature representation 성능을 확인한다. # 3.7. DG: ImageNet-trained CNNs are biased towards texture -ICLR19  - (Citation 미친 논문) 사실 DG는 아니고, ImageNet으로 학습시킨 모델들의 문제점을 확실히 파악하고, `New Stylized Dataset` 을 사용하면 이 문제점을 완화할 수 있다고 말하는 논문이다. - ImageNet을 가지고 학습시킨 CNN이 Shpae/Contenct가 아닌 Strong Texture/Style Bias를 가지는 것을 확인했다. - 자신들이 새롭게 만든 Dataset인 `Stylized ImageNet`을 통해서, Texture/Style가 아닌 Shpae/Contenct를 집중해서 학습하도록 만들 수 있다. # 3.8. DG: Domain Generalization with MixStyle -ICLR21  - AdaIN 개념의 γ (감마) and β (배타) 값을 Random/Mixing 해서 줌으로써 Style-Invariance를 주는 DG - Source domains 간의 `mixing instance level feature statistics ` 를 수행함으로써 DG성능을 올린다. - Introduction and Relative work 정리 1. DG를 성취하는 가장 단순한 방법은, 아주 많은 source domains을 가지고 Dataset을 학습하는 것이다. 이러한 방법은 상업적으로 얼굴인식이나 자율주행 분야에서 큰 효과(성공)을 가져왔다. - Key Sentence 1. Mixing styles of training instances results in novel domains being synthesized implicitly, which increase the domain diversity of the source domains, and hence the generalizability. 2. MixStyle fits into mini-batch training perfectly and is extremely easy to implement. # 3.9. Deep Domain Generalization via Conditional Invariant Adversarial Networks -ECCV18  - `Conditional invariant adversarial network` 를 활용한 DG - 이 논문이 유명한 이유는 Gradient-reversal Layer를 사용하는게 왜 DG에 도움이 되는지 수학 수식으로 구체적으로 증명해놓았기 때문이다. (증명은 굳이 이해하지 않았다) 따라서 Method 및 실험결과 자체만 보면 별거 없다는 생각이 들수도 있다. - 기존의 GRL 논문과 다른 것은 Class-wise Adversarial Nework를 사용했다는 것이 전부이다. # 3.10. Deep domain-adversarial image generation for domain generalisation -AAAI20  - 새로운 Style의 Image를 만들기 위해서, Domain Transformation Network (=New Style Generating Network) 를 활용하는 DG - 중간 초록색 상자를 주목하면 되는데, (Style Transfer Network) T는 \[ **(1)** Label Classificaton 이 잘되게 하는 이미지 **(2)** 어떤 Domain 인지 Domain classifier가 예측하지 못할만한 이미지를 Reconstruction 하도록 학습된다. # 3.11. In Search of Lost Domain Generalization - ICLR21 - Github: (1) [https://github.com/facebookresearch/DomainBed](https://github.com/facebookresearch/DomainBed), (2) [ERM code](https://github.com/facebookresearch/DomainBed/blob/master/domainbed/algorithms.py#L70) , (3) [Algorithms](https://github.com/facebookresearch/DomainBed/blob/master/domainbed/algorithms.py) - 공정한 DG 성능 평가를 위해서 datasets, network architectures, and model selection criteria 통일 방안을 제시한 논문 ` How useful are different DG algorithms when evaluated in a consistent and realistic setting?` - Abstract - `DOMAINBED` 를 통해서, 7개의 Benchmarks, 14개의 알고리즘, 3개의 model selection 기준을 제시한다. - SOTA는 여전히 ERM (Empirical risk minimization) 이다. - 자율주행 장애물 요소: Light, weather, object pose - Biase 이유: Texture statistics, object backgrounds, racial biases - 많은 실험을 통해서 깨달은 takeaways 1. average performance 관점에서는 Carefully tuned ERM 가 SOTA 이다. - ResNet50이 ResNet18 보다 당연히 DG에 좋다. 하지만 기존 알고리즘은 ResNet18을 사용하곤 했다. - 따라서 ResNet50을 사용하고, 하이퍼파라메터를 적절히 튜닝한 ERM 모델이 더 좋은 성능을 가져와 주었다. 2. 14가지 DG 알고리즘 중 ERM 보다 1점 이상 높은 성능을 가지는 것은 없었다. - 새로운 알고리즘이 DG에 좋을 수는 있지만.. 엄격한 방식으로 평가하다면 ERM 보다 높은 DG 성능을 얻은 것은 상당히 challenging 할 것이다. - 대부분의 DG 알고리즘들은 ERM-like performance 을 가졌다. - Our advice to DG practitioners is to use ERM (which is a safe contender) or CORAL (Sun and Saenko, 2016) (which achieved the highest average score) 3. DG에서 Model Selection은 매우 중요하다. 따라서 DG 알고리즘들은 자신의 모델 선택 기준 (model selection criteria) 을 명시해야한다. - (예를 들어서 choosing hyperparameters, training checkpoints, architecture variants 구체적인 것은 논문 추가 참조) - 이렇게 되어 있는데, 이해가 안된다. We observe that model selection with a training domain validation set outperforms leave-one-domain-out cross-validation across multiple datasets and algorithms. This does not mean that using a training domain validation set is the right way to tune hyperparameters. In fact, the stronger performance of oracle-selection (+2.3 points for ERM) suggests headroom to develop improved DG model selection criteria.
- TTT 논문 - Training에서는 Equ(2) 와 같이 2가지 Loss를 사용해서 학습하고, Test에서는 Feature Extractor를 Self-supervised learning으로 Fine-turning한다. # 3.3. DG: Adaptive Methods for Real-World Domain Generalization -CVPR21  - 아주 적은 Unseen target domain data 만으로도 빠르게 적응할 수 있는, `adaptive classifier` 를 목표로 하는 DG - Introduction and Relative work 정리 1. domain invariant를 학습하기 위한 많은 노력이 있었으나, 아직 어떤 모델도 특정한 Test domain에서는 안정된 성능을 보장하지 못한다. 예를 들어 만약에 optimal universal classifier 를 찾았다고 하자. 하지만 Figure 1 처럼 새로운 Target domain과의 큰 adaptivity gap 을 가질 가능성은 여전히 있다. 따라서 우리는 어떤 Domain에서도 적응할 수 있는 adaptive classifier 개발을 목적으로 한다. 2. [7-2019] 논문에서 첫 주장된 kernel mean embeddings (KME) 방법을 사용하여, 아주 적은 unseen sample 만으로도 좋은 성능을 이끌어 낸다. - Approach - Domain Gap은 우리가 어떤 Source로 학습시키더라도 클 수 있다. - 따라서 우리의 목표는 어떤 Test Domain이 들어오더라도 그것에 적은 데이터로 빠르게 적응하는 Classifier를 만드는 것이다. - Domain Emdeding을 활용한 DG 1. kernel mean embeddings 기법을 활용해 각 Domain의 Mean 값을 계산한다. 즉, Domain에 어떤 이미지가 들어가도 그 Domain의 **Info/Style/Centroids**를 출력해주는 Network(Theta)를 개발한다. 이 Network는 Domain의 정보만을 뱉어줄 것이다 2. F_ft는 어떤 Domain이 들어와도, 안정적인 Feature Extact을 해주며, F_mlp에서는 Domain의 Centroid를 고려하여, Domain bias를 고려한 Classifier 역할을 한다. 3. Test time에는 아주 적은 unseen sample 만으로 Domain Prototype을 계산하고, F를 사용해서 Classification을 수행한다. - 추가적으로 (1) LSVRC12+YFCC100M을 기반으로 만든 Real-world domain generalization benchmark: `Geo-YFCC` 소개 (2) 위 방법의 Theoretical Guarantees를 논문에서 추가적으로 제시하므로 필요시 참고할 것. # 3.4. DG: Generalization on Unseen Domains via Inference-time Label-Preserving Target Projections -CVPR21  - classification을 잘 할 수 있는 `manifold space`로 feature를 던져버리는 DG // Image style transfer와 비슷한 느낌의 `Target feature projection` 이라고 표현된다. - Z_s라는 Space를 source data feature manifold라고 하자. classifier는 이 manifold 내부의 feature 만을 classification 잘 할 수 있다. 하지만 unseen target feature는 분명 manifold 내부에 잊지 않을 가능성이 크다. 따라서 target feature를 manifold 내부로 던져 (push) 버리는 G network를 학습하여 사용한다. - Introduction and Relative work 정리 1. 지금까지 DG들은 Source data 만을 사용한다. 하지만 test시에 target example을 1개라도 쓸 수 있다는 점을 무시한다. 그러니 Target과 source와의 gap이 생기는 것은 당연하다. "이러한 상황" 속에서 inference과정 중 target을 효율적이고/적절히 사용하는 방법에 대해서 제안한다. (G 모듈이 추가한 것에 대한 변명인가?) "이러한 상황"이 비판적이라고 말할 수 있지만, 인간에게는 당연한 상황이다. 인간은 unseen object를 만나더라도 감각적으로 similar object를 잘 관련시키는 능력을 가지고 있기 때문에, DG setting도 non-practical 하다고 비판만 하는 것은 문제가 있다. 2. 기존의 DG 방법에는 adversarial learning/ meta learning/ Augmenting the source dataset(:= Style Transfer/ GAN을 통한 Target 같은 data 생성)/ Domain-invariant representations(MMD, CORAL)/ Data augmentaiton (:= Color jittering/ Target domain을 시뮬레이션 한다. 하지만 한계가 존재한다.)/ Self-supervised Learning(jigsaw puzzle) 3. [27], [16], [45] 논문은 이 논문에서 추천하는 위의 방법과는 다른 DG이다. 이것들 보단 우선 최신 논문을 더 읽어, 최신 흐름을 파악하자. - 좀더 자세한 Method는 아래와 같다. (학습과정을 포함한 몇가지가 완전히 이해가지는 않는다. 필요하면 더 찾아보고, 코드를 보자.) - G network는 2가지 형태가 될 수 있다. 논문 결과에서는 VAE 방식에서 더 좋은 성능이 나왔다고 한다. 1. VAE방식: Encoder는 z_i가 들어가서 u~N(0,1)의 Noise가 나와야 하고, Decoders는 Z_i를 reconstruction하면 된다. 2. GAN방식: U가 들어가면 Z_i가 출력되도록 generator를 학습시킨다. (이것은 z_i 정보를 사용하지 않으니, 당연히 성능이 안나오는게 정상 아닐까?) - z\*t 는 z_t 와 cosine distance(코사인 유사도)가 최대한 가까운 (Equ(5)) vector를 generate할 수 있는 u를 찾고, u를 G에 통과시켜 z\*_t 를 생성한다.(= z_t가 z\*t로 push 되었다!) z\*t는 Generator를 통해서 나온 것이기 때문에 manifold 내부에 있을 것이 보장된다고 한다. - Analysis and Implementation 부분에서, z\*_t 을 사용하는 것이 왜 합당한지, 수학적으로 간단히 증명해놓았다. 필요하면 참고하자. # 3.5. Generalizable Semantic Segmentation via Model-agnostic Learning and Target-specific Normalization -arXiv20  - Meta-learning을 활용하는 DG - Method는 과거의 MAML, MLDG 방법을 Segmentaion 에 적용한게 전부이다. - 추가적인 방법이 Target-specific normalization 방법인데, normalization에서 사용하는 mean과 std를 그대로 사용하지 않고 moving average 기법을 사용해 normalization하겠다는 방법이다. 이 과정을 통해서 unseen의 normalization을 mimic할 수 있다고 주장한다. (개인적인 생각으로 Generalization 성능의 작은 향상은 줄 수 있겠지만, 큰 도움은 안 될 듯하다.) - 성능은 AdaptSeg-Net 수준이긴 이고, RobustNet보다는 GTAV->Cityscape 성능은 좋다고 나와 있다. 하지만 실험이 워낙 적고 그렇게 신뢰할만한 실험 결과들을 다수로 제시하지 않았다. 따라서 필요하면 참고하고, 나중에 굳이 성능 비교 논문으로 사용하지 말자. # 3.6. DG: Reducing Domain Gap by Reducing Style Bias -CVPR21  - Style removing(Image에서 Style 정보를 제거한 Feature 변환 or 추출을 목적으로 함)과는 비슷하지만 다르다. CNN이 `Style`에 집중하지 않고 `content`에 집중하도록 유도하는 DG - Introduction and Relative work 정리 1. CNN의 가장 큰 문제점: CNNs’ strong **inductive bias** towards image styles. 따라서 Style-Agnostic Networks (SagNets)를 사용해서 class categories에서 style encodings을 분리한다 2. 인간의 Vision은 객체의 Only Contents를 보고 판단을 한다. (한장의 객체 사진으로 Real world, 만화, 그림 등의 객체를 모두 동일한 것으로 판단할 수 있다.) 하지만 CNN은 Content만을 보고 판단하지 않는다. Style, Texture 또한 많이 보고 판단한다. 이 사실을 정확히 증명하고 분석한 논문이 아래의 \[#3.7\] 이다. 따라서 현재의 CNN은 Style에 민감하고 Domain의 변화에 민감할 수 밖에 없다. 3. 따라서 본 논문은 이러한 문제를 해결하기 위해 모델을 개발하였으며, 특히 multiple domains 을 사용하지 않고 `Intrinsic bias` 를 제거하려고 노력하였다. 4. 이 논문의 Method는 기존 Adversarial Learning 기법들과는 조금 다르다. 확실한 Discriminator가 없고, Classifier(G_s)가 Discriminator와 비슷한 역할을 하게 만들고, Adversarial Learning은 G_s가 판단을 헷갈리게 하는 방식으로 진행한다. - 핵심 Method 설명 1. Content-Biased Learning: G_c (Centent Classifier) 를 학습하기 위해, Style randomization 수행 2. Adversarial Style biased Learning: G_f (Feature Extractor) 를 학습하기. G_s를 통과하고 나온 vector가 1/K x ones(K) 이되도록, G_f가 학습된다. 구체적으로, G_f의 Feature map이 Label에 대한 정보를 Feature의 Mean, Std에 담지 못하게 유도함으로써, G_s (discriminator) 가 Classification을 잘하지 못하도록 만든다. 3. 만약 UDA 세팅으로 하고 싶다면, x는 target dataset(unlabled)의 이미지이다. Style Randomization을 하든 안하든, Classifier를 통과하고 나온 Feature는 유사해야한다는 사실을 이용한다. ## 3.6.1. A style-based recalibration module for convolutional neural networks -ICCV19  - CBAM과 같은 목적의 논문. Style에 좀 더 집중한 Style-based Recalibration Module (SRM) - 본래 이미지의 Style정보를 활용해서 Feature에 Style 혹은 Contencts Attention 효과를 얻어, `the representational ability of a CNN` 을 향상시키고자 한다. - Recognition 혹은 Style Transfer로 Feature representation 성능을 확인한다. # 3.7. DG: ImageNet-trained CNNs are biased towards texture -ICLR19  - (Citation 미친 논문) 사실 DG는 아니고, ImageNet으로 학습시킨 모델들의 문제점을 확실히 파악하고, `New Stylized Dataset` 을 사용하면 이 문제점을 완화할 수 있다고 말하는 논문이다. - ImageNet을 가지고 학습시킨 CNN이 Shpae/Contenct가 아닌 Strong Texture/Style Bias를 가지는 것을 확인했다. - 자신들이 새롭게 만든 Dataset인 `Stylized ImageNet`을 통해서, Texture/Style가 아닌 Shpae/Contenct를 집중해서 학습하도록 만들 수 있다. # 3.8. DG: Domain Generalization with MixStyle -ICLR21  - AdaIN 개념의 γ (감마) and β (배타) 값을 Random/Mixing 해서 줌으로써 Style-Invariance를 주는 DG - Source domains 간의 `mixing instance level feature statistics ` 를 수행함으로써 DG성능을 올린다. - Introduction and Relative work 정리 1. DG를 성취하는 가장 단순한 방법은, 아주 많은 source domains을 가지고 Dataset을 학습하는 것이다. 이러한 방법은 상업적으로 얼굴인식이나 자율주행 분야에서 큰 효과(성공)을 가져왔다. - Key Sentence 1. Mixing styles of training instances results in novel domains being synthesized implicitly, which increase the domain diversity of the source domains, and hence the generalizability. 2. MixStyle fits into mini-batch training perfectly and is extremely easy to implement. # 3.9. Deep Domain Generalization via Conditional Invariant Adversarial Networks -ECCV18  - `Conditional invariant adversarial network` 를 활용한 DG - 이 논문이 유명한 이유는 Gradient-reversal Layer를 사용하는게 왜 DG에 도움이 되는지 수학 수식으로 구체적으로 증명해놓았기 때문이다. (증명은 굳이 이해하지 않았다) 따라서 Method 및 실험결과 자체만 보면 별거 없다는 생각이 들수도 있다. - 기존의 GRL 논문과 다른 것은 Class-wise Adversarial Nework를 사용했다는 것이 전부이다. # 3.10. Deep domain-adversarial image generation for domain generalisation -AAAI20  - 새로운 Style의 Image를 만들기 위해서, Domain Transformation Network (=New Style Generating Network) 를 활용하는 DG - 중간 초록색 상자를 주목하면 되는데, (Style Transfer Network) T는 \[ **(1)** Label Classificaton 이 잘되게 하는 이미지 **(2)** 어떤 Domain 인지 Domain classifier가 예측하지 못할만한 이미지를 Reconstruction 하도록 학습된다. # 3.11. In Search of Lost Domain Generalization - ICLR21 - Github: (1) [https://github.com/facebookresearch/DomainBed](https://github.com/facebookresearch/DomainBed), (2) [ERM code](https://github.com/facebookresearch/DomainBed/blob/master/domainbed/algorithms.py#L70) , (3) [Algorithms](https://github.com/facebookresearch/DomainBed/blob/master/domainbed/algorithms.py) - 공정한 DG 성능 평가를 위해서 datasets, network architectures, and model selection criteria 통일 방안을 제시한 논문 ` How useful are different DG algorithms when evaluated in a consistent and realistic setting?` - Abstract - `DOMAINBED` 를 통해서, 7개의 Benchmarks, 14개의 알고리즘, 3개의 model selection 기준을 제시한다. - SOTA는 여전히 ERM (Empirical risk minimization) 이다. - 자율주행 장애물 요소: Light, weather, object pose - Biase 이유: Texture statistics, object backgrounds, racial biases - 많은 실험을 통해서 깨달은 takeaways 1. average performance 관점에서는 Carefully tuned ERM 가 SOTA 이다. - ResNet50이 ResNet18 보다 당연히 DG에 좋다. 하지만 기존 알고리즘은 ResNet18을 사용하곤 했다. - 따라서 ResNet50을 사용하고, 하이퍼파라메터를 적절히 튜닝한 ERM 모델이 더 좋은 성능을 가져와 주었다. 2. 14가지 DG 알고리즘 중 ERM 보다 1점 이상 높은 성능을 가지는 것은 없었다. - 새로운 알고리즘이 DG에 좋을 수는 있지만.. 엄격한 방식으로 평가하다면 ERM 보다 높은 DG 성능을 얻은 것은 상당히 challenging 할 것이다. - 대부분의 DG 알고리즘들은 ERM-like performance 을 가졌다. - Our advice to DG practitioners is to use ERM (which is a safe contender) or CORAL (Sun and Saenko, 2016) (which achieved the highest average score) 3. DG에서 Model Selection은 매우 중요하다. 따라서 DG 알고리즘들은 자신의 모델 선택 기준 (model selection criteria) 을 명시해야한다. - (예를 들어서 choosing hyperparameters, training checkpoints, architecture variants 구체적인 것은 논문 추가 참조) - 이렇게 되어 있는데, 이해가 안된다. We observe that model selection with a training domain validation set outperforms leave-one-domain-out cross-validation across multiple datasets and algorithms. This does not mean that using a training domain validation set is the right way to tune hyperparameters. In fact, the stronger performance of oracle-selection (+2.3 points for ERM) suggests headroom to develop improved DG model selection criteria.