【DG】 Survey DG papers 2 - RobustNet and 15 relative papers
 # 2. RobustNet - Main Goal: Multi Source에 의지하지 않고, **Domain/ Appearance/ Weather/ Location/ Environment/ illumination/ Style Invariance 가진 모델 만들기!** 단, **'domain-specific style' and 'domain-invariant content' 를 분리하여, content에는 방해가지 않도록 한다.** - DNN에서 어떤 것이 Style 정보를 담고 있는가? Channel wise Correlation Matrix에 집중! (저자는 IBN-net에서는 IN이 DG를 위해 불충분하다며, Correlation을 고려하지 않았다고 했다. 하지만 내가 조사한 바에 따르면 Style에 관련된 요소는 더욱 많다. (DG survey post 1.14 참조) ) - Whitening Transformation 이란, **초기 Layer의 Feature map에 대해 채널 방향 공분산 행렬이 단위행렬이 되도록 만든 변환**이다. (==Feature map (CxHxW)를 [HW 백터 C개] 로 변환한 후, C개의 백터들에 대한 Covariance Matrix 를 Identity Matirx 형태가 되도록 하는 것이다.), 이렇게 하면 **이미지의 Style 정보가 제거 된다는 가설**이 있기 때문에, 이 논문에서는 WT를 적절히 적용하기 위한 노력들을 하고 있다. 1. Instance Whitening Loss (IW loss): Covariance Matrix **전체** == Identity Matrix 2. Margin-based relaxation of whitening loss (IRW loss): Covariance Matrix 전체 == Identity Matrix **+ ε (엡실론)** 3. Instance selective whitening loss (ISW loss): Covariance Matrix **일부 (domain-specific element position)** == Identity Matrix # 2.0 Relative work & Paper list 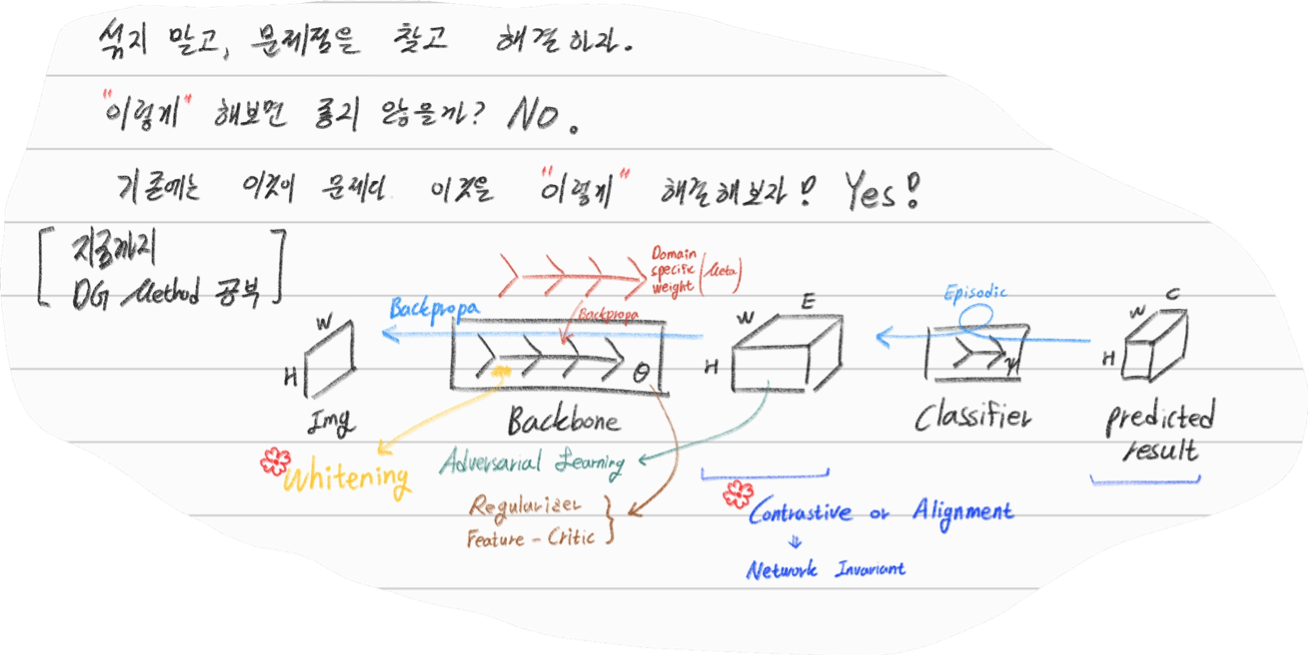 - **Multiple Source Domains** DG 논문들: Shared representation (general feature extractor) 학습하기. 1. 아래 과거 DG들의 문제점: 어쨋든 Multi Domain에 너무 많이 의지. Sources 갯수에 성능 변화 큼. 2. (#2.7) [29] Domain generalization with adversarial feature learning -CVPR18 3. (#2.10) (#2.10) [10] Domain generalization via model-agnostic learning of semantic features -NIPS19 4. (#2.6) [39] Unified deep supervised domain adaptation and generalization -ICCV17 5. (#1.8) [40] Domain generalization via invariant feature representation. -ICML13 6. (#1.9) [15] Domain generalization for object recognition with multi-task autoencoders -ICCV2015 7. (#2.5) [27] Learning to generalize: Meta-learning for domain generalization -arXiv17 8. (#2.8) [2] Metareg: Towards domain generalization using metaregularization -NIPS18 9. (#2.11) [28] Episodic training for domain generalization -ICCV19 10. (#2.12) [33] Feature-critic networks for heterogeneous domain generalization -ICML19 11. Generalizing Across Domains via Cross-Gradient Training -ICLR18 12. Generalizing to unseen domains via adversarial data augmentatio -NIPS18 13. (#2.13) Domain generalization by solving jigsaw puzzles -CVPR19 - **Sementic Segmentation DG** 1. [64] 2. [44] IBN net - **Correlation Matrix(CM)** 은 Image Style 정보를 담고 있다. 1. (#2.3) Texture synthesis using convolutional neural networks -NIPS15 2. (#2.4) Image style transfer using convolutional neural networks -CVPR16 (= A neural algorithm of artistic style) 3. domain adaptation [51, 57] 4. networks architecture [36, 45, 21, 56] - **channel-wise mean and variance** 이 담고있는 Style 정보를 이용하는 논문 [23], [25] (WT사용하는 [7]보다 성능 낮은) - **Whitening Transformation(WT)** 가 이미지의 Style 정보를 제거한다는 가설 1. (#2.2) Image-to-Image Translation via Group-wise Deep Whitening-and-Coloring Transformation -CVPR19 2. (#2.1) Universal Style Transfer via Feature Transforms -NIPS17 3. domain adaptation [45, 57, 51] 4. approximating the whitening transformation matrix using Newton’s iteration [22, 21] 5. WT의 단점1: diminish feature discrimination [45, 61] 6. WT의 단점2: distort the boundary of an object [31, 30] - **성능 비교 논문** 1. IBN net 2. Iterative normalization: Beyond standardization towards efficient whitening -CVPR19 # 2.1 WT&ST: Universal Style Transfer -NIPS17 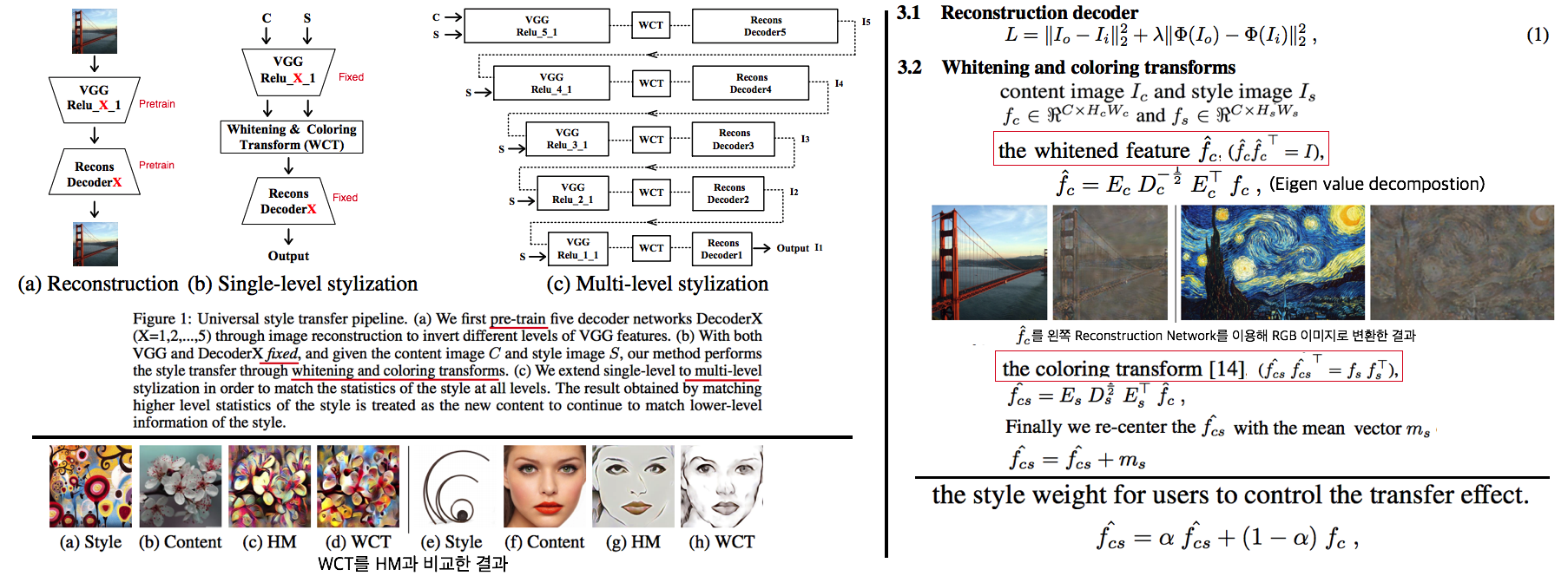 - 기존 Style Transfer 모델들 문제점: Unseen style에 대한 generalizaing 능력과 visual quality가 부족하다. - Feature Covariance Matrix를 이용하는 (2가지 Feature transforms) `(1) whitening (2) coloring` 를 사용해서 이 문제를 해결하고자 한다. - WCT (Whitening and Coloring) 으로 최종 만들어진 Feature를 Reconstruction 해서 RGB 이미지를 만든다. 결과로 확인해 보면, WCT 이 HM(histogram matching) 을 사용한 것보다 Style 특성을 더 강렬하게 담아주는 것을 확인할 수 있었다. (= Covariance Matrix matching 이 HM 보다 더 강한 Style 정보를 전달해 주는가보다) - (Me: Recon된 결과를 보아하니, WT를 통해서 확실히 Feature에서 Style 정보를 제거해준다. (**Style이 아니라 Color정보를 지우는 것 뿐인가? Weather과 같이 Color 그 이상의 Style 정보를 지우러면 어떻게 해야할까?** --> **Weather-wise dataset을 가지고 각 Weather 마다 Deeplab을 fine-tuning을 한 후, Con, FC, Covariance, IN,BN 파라미터의 변화가 어디서 가장 많이 일어놨는지 확인해보면 되지 않을까??)** # 2.2 WT&ST: Image-to-Image Translation via Group-wise DWCT Transformation -CVPR19 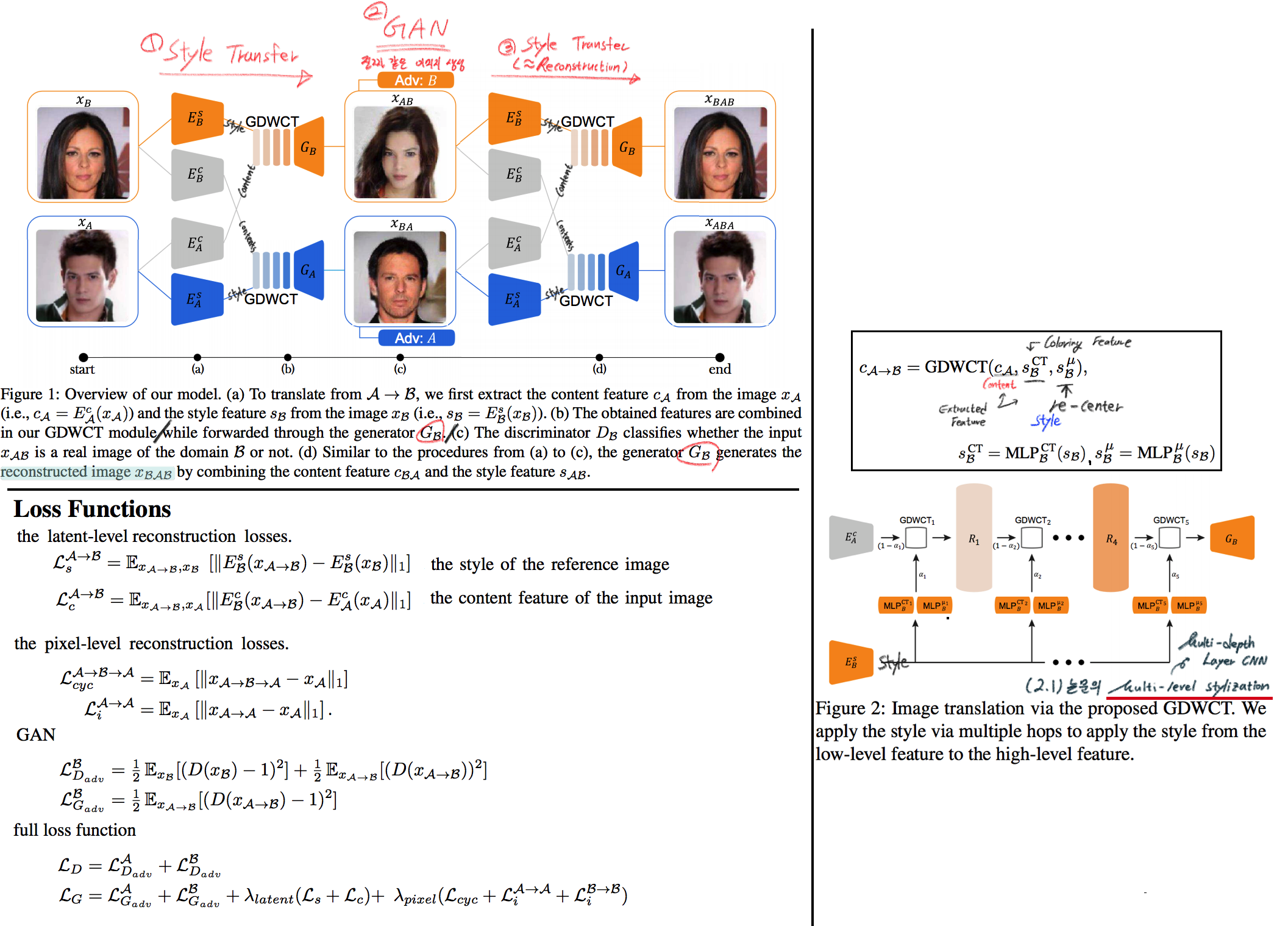 - Motivation: MUNIT (Adaptive IN) 에다가, WCT (whitening and coloring Transform) 기법을 추가하면 어떨까?? Eigen value decomposion말고 Deep WT과 Deep CT를 적용한다. - (2.1) 논문의 내용을 베이스로 사용한다. WT과 CT를 Backpropa가 안되는 Eigen value decomposition을 사용하지 말고, Deep Learning 기법으로 사용해보자. 우선 DWCT 에 대해 아래와 같이 자세히 알기 전에, DWCT가 잘된다는 가정하에 위의 전체 아키텍처를 학습시켜서, Image Tranlation 모델을 만들어 낸다. - 위 사진의 오른쪽과 같이 Multi level (depth) 구조를 사용하는 이유는 논문에서 주장하는 이 가설 때문이다. (the low-level feature captures a local fine pattern, whereas the high-level one captures a complicated pattern across a wide area) 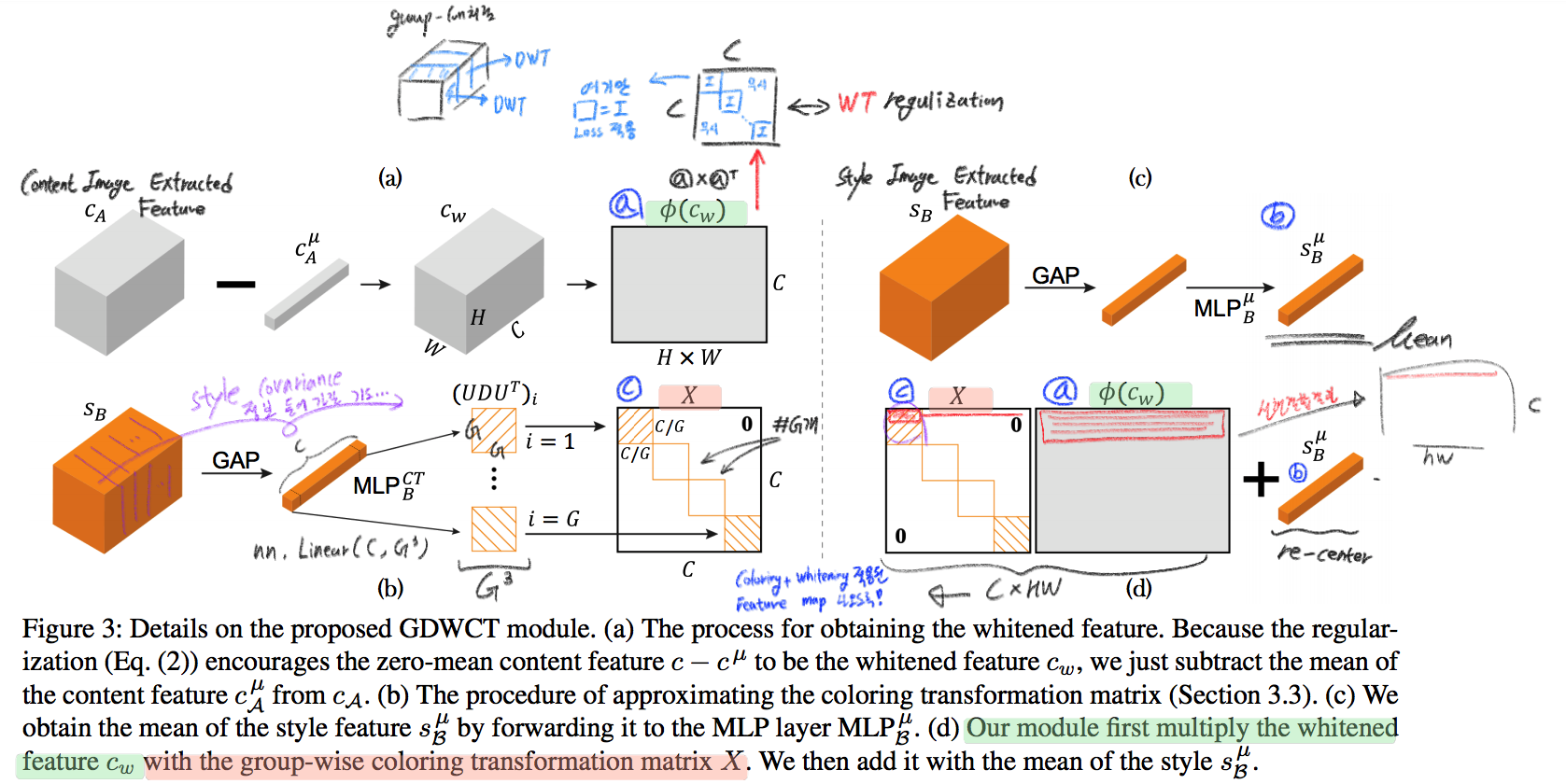 - GDWCT 를 하는 과정을 그림으로 표현했다. WT는 RobustNet에서 이미 잘 설명했다. 하지만 CT는 음.. 아직 잘 모르겠다. 수식을 봐도 잘 모르겠다. 근본적인 CT의 목표는 "Contents Feature 의 Covariance Matric == WCT Feature 의 Covariance Matirc" 로 만드는 것이다. 이것을 이와 같이 구현했다. 정도만 이해하자. # 2.3 ST: Texture synthesis using convolutional neural networks -NIPS15 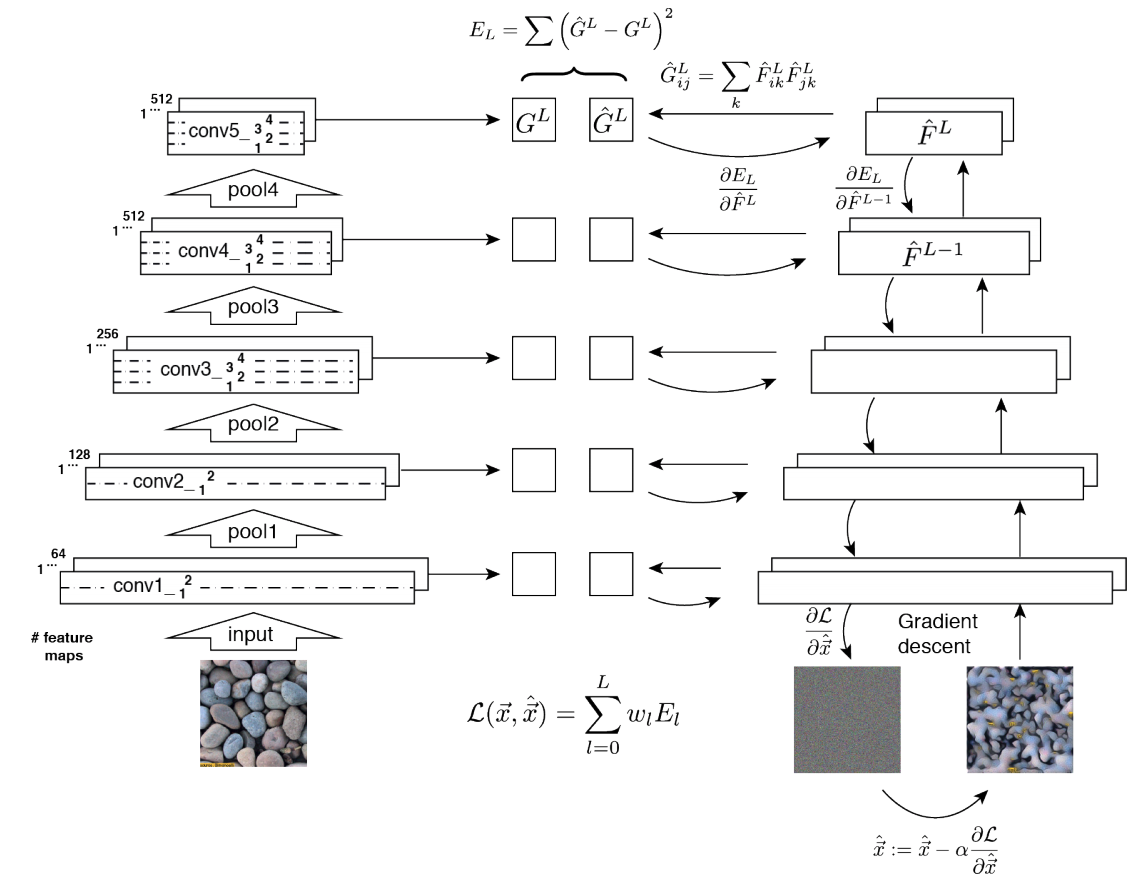 - One spatial summary statistic: the **correlations** between feature responses in each layer of the network 을 직접 이용하는 첫 논문. 자세한 내용은 아래의 2.4 논문과 비슷하다. - 이 논문에서 Channel-wise Correlation matrix를 사용한 이유는 1. [2000년대 논문](https://link.springer.com/article/10.1023/A:1026553619983) 에서 Image Texture를 탐지하기 위해서, 이미지 자체의 Correlation 정보를 이용했었다. 2. Texture는 spatial information에 대해서 agnostic 해야하는데 Correlation이 이 조건을 만족한다. 다시 말해, 저자는 feature maps에서 the spatial information 를 제거하면서 Texture 정보를 담고 있을 만한 지표가 Correlation이라고 생각었나보다. # 2.4 ST: Image style transfer using convolutional neural networks -CVPR16 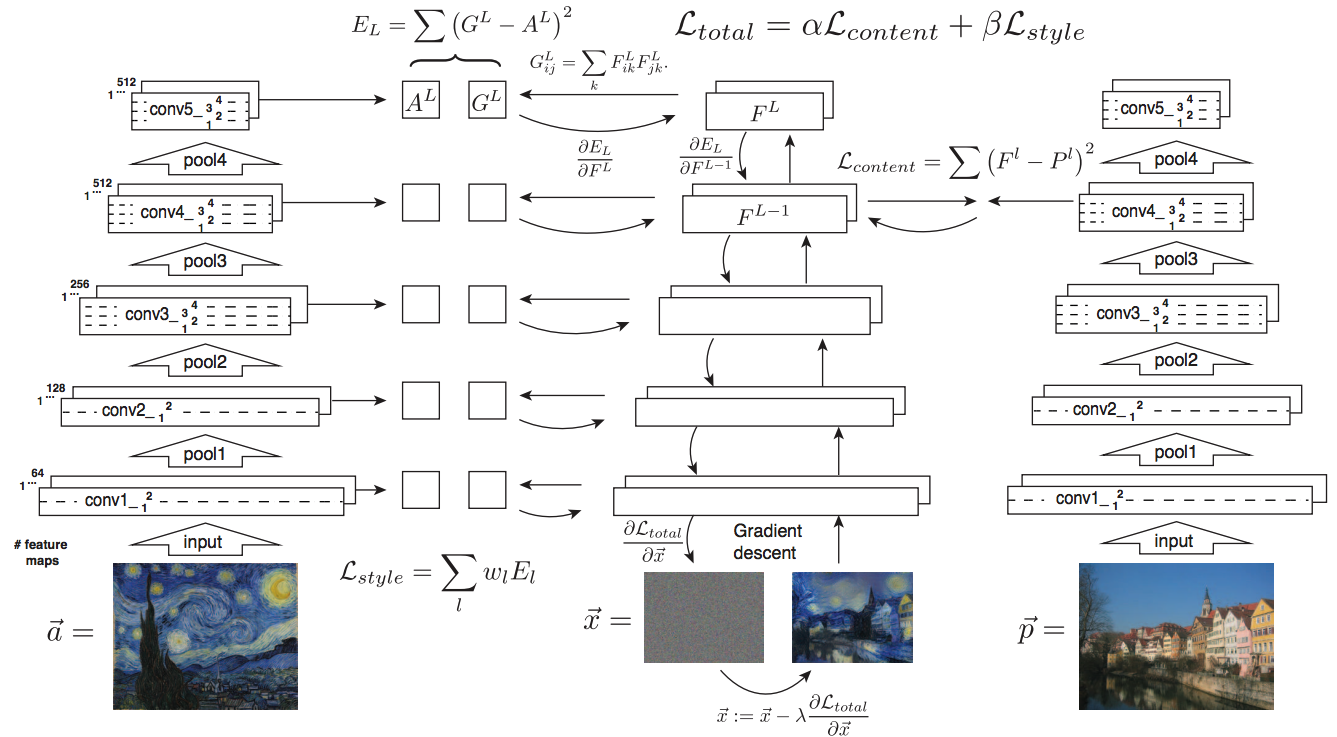  - Style Image 를 생성하는 방법은 하나의 Recon Network를 사용하는게 아니라, **Gradient를 직접 활용해 이미지를 생성**하는 아주 고전적인 방법이다. - 위 실험을 통해서 아래의 2개를 가정을 증명할 수 있다. - Content Loss를 적용하기 위해서는 Sauared-error loss (Euclidean Distance) 정도만 적용해도 무방하다. - Style(Texture) Loss는 Channel-wise Covariance Matrix를 사용한다. (Feature map의 channel == c 일때, c개의 채널 각각은 서로다른 필터(k x k x c_input) 에 의해 생성된 결과이라는 사실을 상기하자) # 2.9. MAML 먼저보기! # 2.5 DG: Learning to generalize: Meta-learning for domain generalization:MLDG -arXiv17 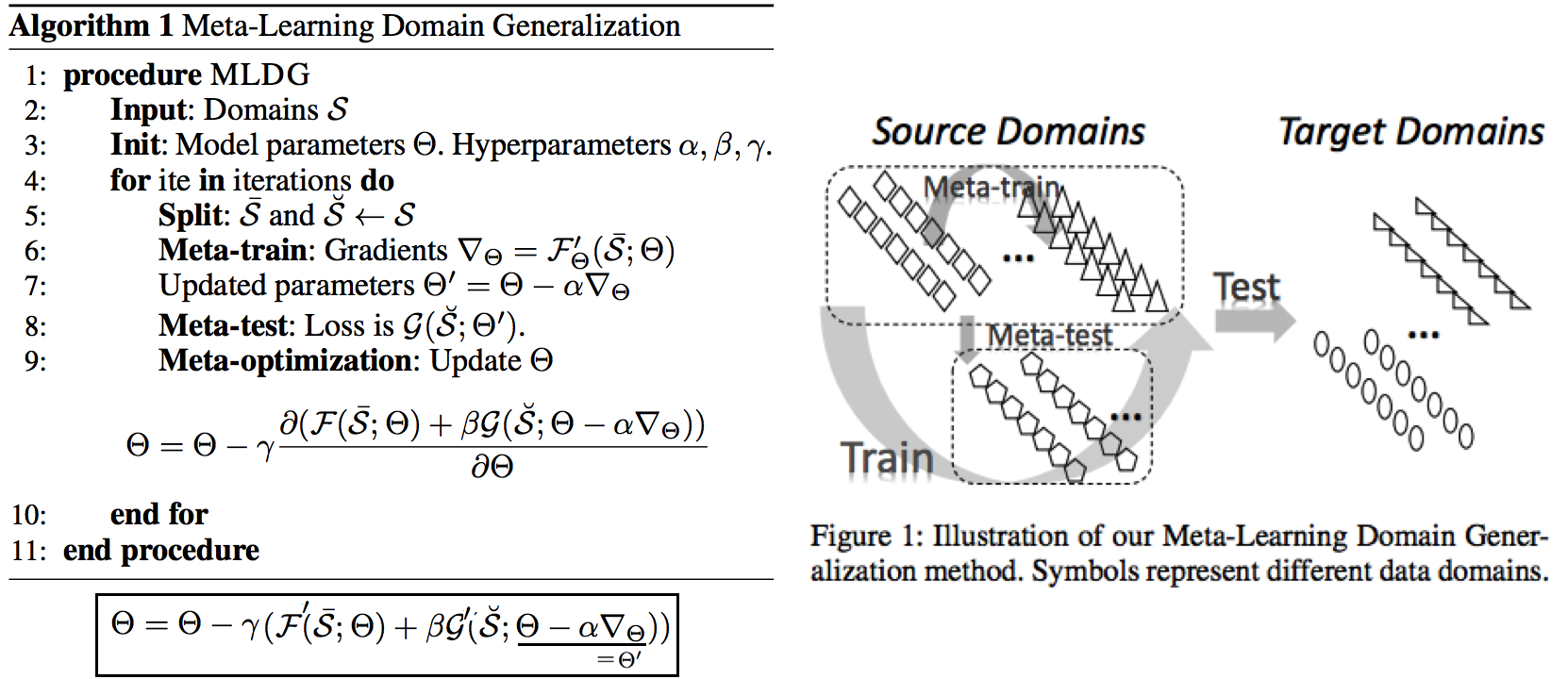 - `Meta Learning` 을 활용한 D. 그냥 Source domains 데이터를 그냥 한꺼번에 Supervised로 학습하지말고 (그냥 우걱우걱 학습하지 말고), Train-Test 과정을 시물레이션 함으로써 Network가 해당 시뮬레이션을 통해서 좀 더 옯바른 방향으로 학습되도록 유도한다. Loss를 1차적으로 거는게 아니라, 2차적으로 걸어준다. MetaTrain set에서 학습되는 Loss에 대해서, MetaTest set에서 학습되는 Loss를 추가적으로 걸어주는 방식이다. - [meta-learning method(이란?)](https://talkingaboutme.tistory.com/entry/DL-Meta-Learning-Learning-to-Learn-Fast) 을 적용한 첫 DG 모델이라고 할 수 있겠다. - a model agnostic training procedure(=미니배치 안에 가상 Target이미지 사용) 을 적용함으로써 train/test domain shift 를 시뮬레이션 할 수 있다. 아래의 알고리즘을 사용해서 모델을 학습시킨다. [코드로 공부](https://github.com/HAHA-DL/MLDG/blob/master/model.py#L312) `total_loss = meta_train_loss + meta_val_loss * flags.meta_val_beta` - S = 6 source domains into V = 2 meta-test and S − V = 4 meta-train domains. 데이터셋 분리는 다음과 같이 한다. - Why! 왜 이러한 작용이 Generalization에 도움을 줄까??? 그대로 전체 Data에 대한 Gradient를 주면, 한쪽 방향으로 쏠리고 Source Optimization이 일어난다. 중간중간에 Meta-dataset에 대한 Loss를 추가해줌으로써 One-dataset-overfitting-optimization 을 피하게 만들어 준다. # 2.6 DG: Unified deep supervised domain adaptation and generalization -ICCV17  - `Contrastive Learning`을 활용한 DG - Task: Supervised DA or DG in Classification. using Contrastive Loss - 만약 UDA를 한다면, (#1.3) MMD 기법으로 위 Equ(2) 를 적용한다. (p 는 softmax 정도로만 생각하자) # 2.7 DG: Domain generalization with adversarial feature learning -CVPR18 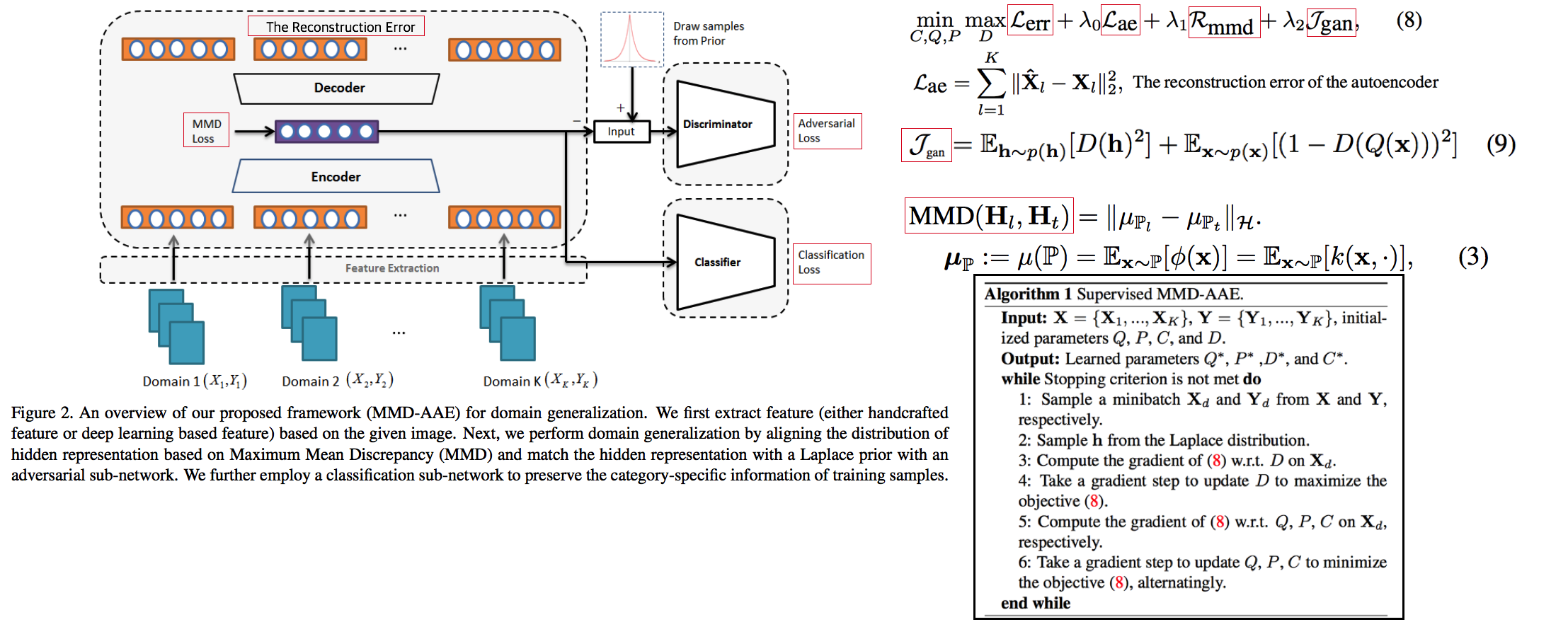 - `MMD regularizing Adversarial Learning` 을 활용한 DG 효과를 더욱 이끌어 낸다. - "모든 Domain을 고려하면, Hidden code는 결국 특정 분포(Ex.the Laplace distribution)를 따를 것이다" 라는 가정을 이용 - Total Loss 1. Reconstruction Loss: Hidden Code가 Input Image 로 reconstruction 잘 되었는가? (Contenct 유지 유도) 2. Classification Loss (Contenct 유지 유도) 3. Adversarial Loss: MMD에 의해서 generalization 성능은 높아질 수 있지만, 오직 Source domains에만 Overfitting 되는 것을 막아준다. Discriminator는 a prior distribution에서 나온 Sample 인지, Hidden code 인지 분별하는 역할을 하고, Discriminator가 혼동하도록, 즉 Hidden code가 a prior distribution에서 나온 값과 비슷하도록 유도해 준다. 여기서 prior distribution(=arbitrary distribution)은 **the Laplace distribution** 을 사용했다. Gaussian distribution and the Uniform distribution 를 사용하는 것보다 성능이 좋았다고 한다. (Generalization And Not-overfitting 유도) 4. [MMD Loss](https://github.com/YuqiCui/MMD_AAE/blob/master/utils/losses.py): 어떤 domain 이디든 Hidden Code가 비슷한 Embeding Space (공간)에 위치하도록 도와줌. (Generalization 유도) # 2.8. DG: Metareg: Towards domain generalization using metaregularization -NIPS18   - `meta regularization` 이라는 새로운 신경망을 사용한 DG. - MAML가 DA이지만, 우리는 DG이고, MLDG의 Generalization cost가 많이 필요하지만 우리는 Fixed F 를 사용해서 Cost 낮다. - Regularizer 라는 신경망을 먼저 이렇게 정의한다. "Generalization에 도움을 주는, Task Network가 하나의 Domain으로 학습될 때 overfitting 되지 않도록 규제해주는 역할을 하는 신경망" 처음에는 Φ(파이) 신경망을 무작정 사용하고, 이게 Iteration을 돌수록 점점 저런 역할을 하는 신경망이 될거라고 기대한다. (강화학습의 Policy, Q network 처럼.. 처음에는 아무 역할도 안하는 신경망이지만, 점점 원하는 역할을 하는 신경망이 되도록 유도한다.) - (**주의! 코드가 이상하니 신경쓰지 말기 // (#2.12) 내용과 거의 일치하다 **) novel regularization function in meta-learning framework: 아래의 순서로 Regularizer(nn.Linear( T network weight, 1))가 학습된다. [코드 확인](https://github.com/elliotbeck/MetaReg_PyTorch/blob/master/train.py#L148) Regularizer는 T network에 새로운 Loss를 줌으로써 T가 Generalization 되도록 도와주는 신경망이다. T network를 받고 Loss값이 스칼라값으로 나오는 신경망이다. 다시말해, **Generalization을 위해서 a domian을 학습하는 동안, "b와 c domain도 고려하니까 적당히 학습해!" 라는 느낌으로 beta 갱신에 사용된다** 1. ([Step1](https://github.com/elliotbeck/MetaReg_PyTorch/blob/master/train.py#L152)) Base model updates: 각 Domain data를 사용해서, 공통된 F 그리고 T1~Tp 모델을 학습시킨다. 2. Episode creating: 랜덤으로 2개의 domain을 선택해서, (1) metatrain set (`a` domain) (2) metatest set (`b` domain) 으로 설정한다. 3. ([Step2](https://github.com/elliotbeck/MetaReg_PyTorch/blob/master/train.py#L167)) Re-traing using metatrain set: 위 1번에서 학습되된 `a` domain 으로 파라미터로 Init한 F+Ta 모델을 `l` gradient steps 까지. `a` domain dataset으로 F+Ta를 학습시킨다. 4. ([Step3](https://github.com/elliotbeck/MetaReg_PyTorch/blob/master/train.py#L173)) Regularizer updates: model_regularizer는 input으로 T의 weight가 들어가고 output이 스칼라값이 나오는 nn.Linear 인데, 이 [스칼라값이 Loss로 동작](https://github.com/elliotbeck/MetaReg_PyTorch/blob/master/train.py#L186)해서 "Final F+T"를 update해준다. 신기하게도 model_regularizer는 `b` 이미지를 사용해 F+Ta 신경망에 의해서 계산 Loss값 backward 값으로 update된다. # 2.9. Meta: Model-Agnostic Meta-Learning for Fast Adaptation:MAML-ICML17 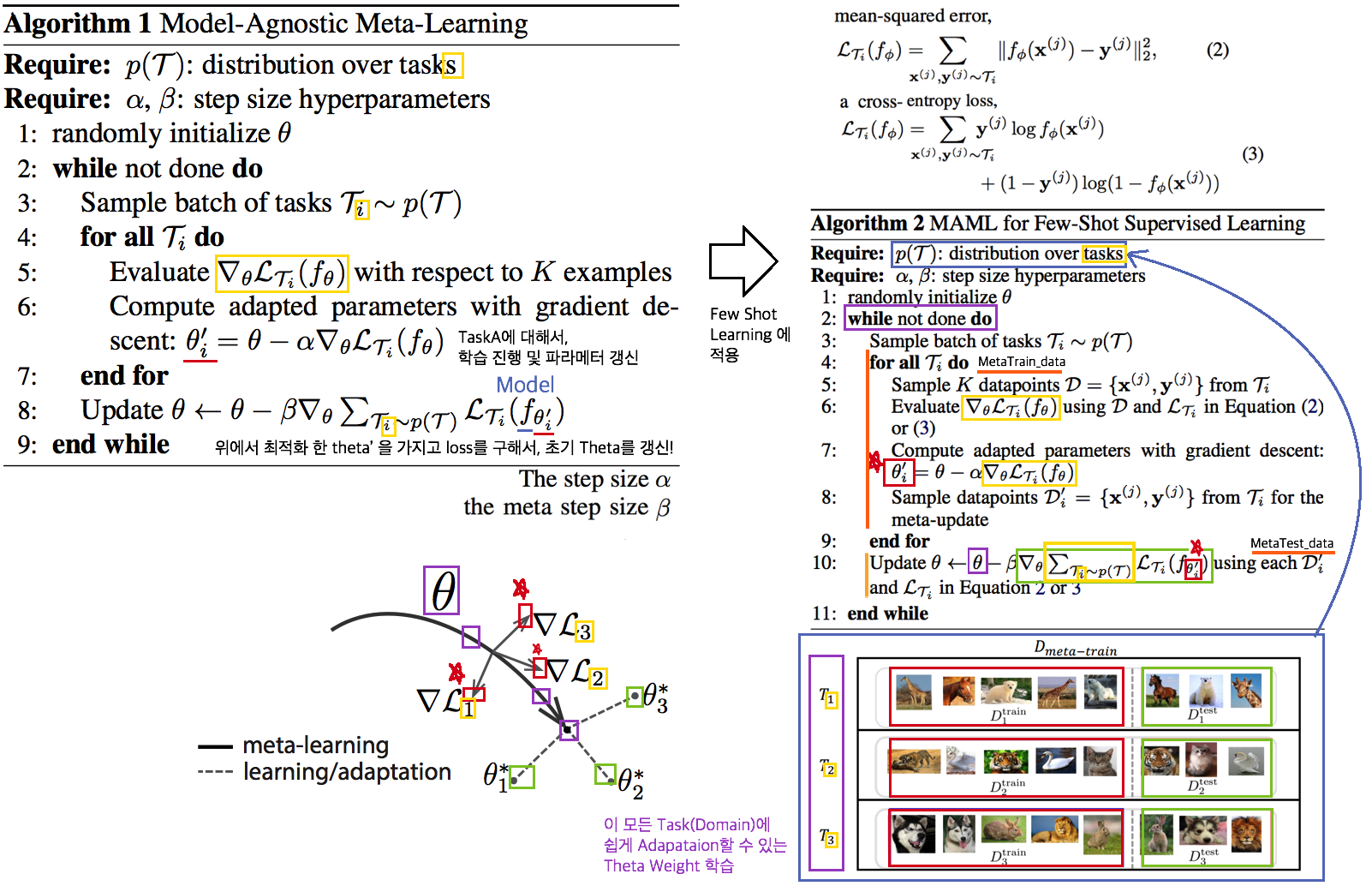 1. Tasks(Domains)를 사용해서, 어떤 Task에도 빠르게 adaptation 할 수 있는 pretrained-model 만들기를 목표로 한다. 2. The objective of the MAML approach is to find a good initialization θ such that few gradient steps from θ results in a good task specific network. (모델의 init weight(=Theta(보라색))를 적절하게 만드는 방법을 소개한다. 이 weight 는 새로운 Task에 init으로 사용해서 빠르게 적응/일반화 가능하다.) 3. 가장 아래 보라색 지점(theta)에서 파라미터 갱신을 하기 위해, 각 Task에 대해 학습한 결과인 빨간색 (theta')를 사용해서, 모든 Task에 적합한 파라미터의 지점 (연두색의 중간지점 쯤) 으로 Theta가 갱신되도록 유도하다. 4. 지금은 이해하기 힘들지만, 엄청 높은 Citation과 많은 논문에서 이 기법을 적용한다. 따라서 차근차근 이해하려고 노력해보자. [참고 유투브](https://www.youtube.com/watch?v=fxJXXKZb-ik) 5. PS. Few-shot-learning이란? N-way(Classes), K-shot(Samples) 총 NK개의 데이터만 사용해서 모델이 적절히 학습되게 만드는 알고리즘을 찾는 연구. 6. (#2.10 논문에서 차용) Intuitively, the training procedure/ is learning/ how to generalize/ under domain shift./ In other words, parameters/ are updated/ such that/ future updates with given source domains/ also improve/ the model/ regarding some generalizable aspects/ on unseen target domains. (직관적으로 이러한 학습 절차는 Domain shift를 고려한 generalization 이다. 다시말해서, 처음 파라미터 업데이트된 `theta'` 는 '미래의 파라미터 업데이트'를 위해서만 잠시 존재한다. '미래의 파라미터 업데이트'는 (Unseen target domains을 위한 Generalization 성능을 위해) `theta'` 와 MetaTest dataset을 활용해 구해진 gradient로 업데이트가 이뤄진다.) # 2.10. DG: Domain Generalization via Model-Agnostic Learning of Semantic Features -NIPS19  1. `MAML meta-learning`, `Contrastive Learning` 을 활용한 DG 2. 즉. a model-agnostic learning: (domain shift 를 시뮬레이션 하기 위해서) **meta-train and meta-test** procedures (to expose the optimization to domain shift. \|#D_train\| = 2 and \|#D_test\| = 1. 3. 궁극적 목표: **consistent features** 얻기 (:= Domain Invariance) 4. two complementary losses를 통해서 semantic features via global class alignment and local sample clustering 을 만들어 낸다. - `soft confusion matrix`: 각 Domain의 Class cluster 구조관계가 유사해야한다. - `metric-learning component`: Domain에 상관없이 같은 Class는 당기고 다른 Class는 밀어서, Class 마다의 Cluster를 가져야 한다. 5. Global Class Alignment Objective ([코드](https://github.com/biomedia-mira/masf/blob/master/utils.py#L107)) - MetaTrain_dataset에서의 각 Domain 각 Class 의 Centoids 위치가, MetaTest_dataset에서도 유사해야 한다. 즉 각 Domain 마다 Class centrois 위치는 비슷해야 한다. - (그림에서는 Covariance, Position simillarity 같이 생겼지만 아니다. ) 6. Local Sample Clustering Objective - 모든 Domain에 대해서 Class 별 Contrastive Loss # 2.11. DG: Episodic Training for Domain Generalization -ICCV19  - `Backprobagation` 의 흐름을 바꿔 학습시키는 DG - 현재 domain과는 정반대의 partner model과 상호작용하면서, Domain shift를 시뮬레이션 한 episodic로 Traning 진행했다. - Equ(5) 에서 ψ_r 은 Label space를 어떤 것을 가지든 상관없는 Classifier이다. 따라서 `heterogeneous domains generalization` 이 된 Feature Extractor (theta) 획득이 가능하다. - Figure 그림 추가 설명 - Figure1: Aggregation multi domain learning (AGG) 그냥 모든 Domain을 한꺼번에 묶어서 학습시킨다. - Figure2: N개의 Domain, N개의 모델 - Figure3: 하나의 AGG 모델을 두고, Figure2에서 Domain Sepecific Model을 가져와서 AGG의 Generalization 성능을 높힌다. - Figure4: 하나의 AGG 모델을 두고, heterogeneous DG Feature Extractor (Theta, Equ(5))를 학습시키고, 원하는 Classifier(ψ) 를 Equ(4)로 학습시킨다. # 2.12. DG: Feature-critic networks for heterogeneous domain generalization -ICML19  - 한 줄 정리: Regularizer Network으로써, Feature-critic Network를 사용한다. - Feature-critic Network 1. "현재의 Feature Extractor 파라미터가, MetaTest-domain의 성능일 올려줄지 아닐지"를 예측해주는 네트워크이다. 2. 이 Network를 사용해 Train 과정에서 Ausilliary loss를 뽑아내고, Validation 과정에서 이 Network를 update한다. 1. Equation 설명 1. Equ (2): 전체 Classification 모델을 학습시키는데 사용할 Loss 2. Equ (6), (7): 다양한 종류의 h(w) = Feature-critic Network 3. Equ (3): h(w)의 parameter인 w가 가져야할 조건. (Meta_test Domain에서 더 좋은 결과를 가지도록 Loss를 유도해 줘야 함) 4. Euq (5): h(w)를 optimize 하기 위해서, 사용하는 h(w) Loss function. Old theta보다 New theta에 의해서 Validation 이미지의 예측결과가 더 좋아지도록 유도하면서, 동시에 Ausilliary loss에 의해서 새롭개 갱신된, New theta가 generalization 능력을 갖춘 theta가 되도록 유도한다. # 2.13. DG: Domain Generalization by Solving Jigsaw Puzzles -CVPR19 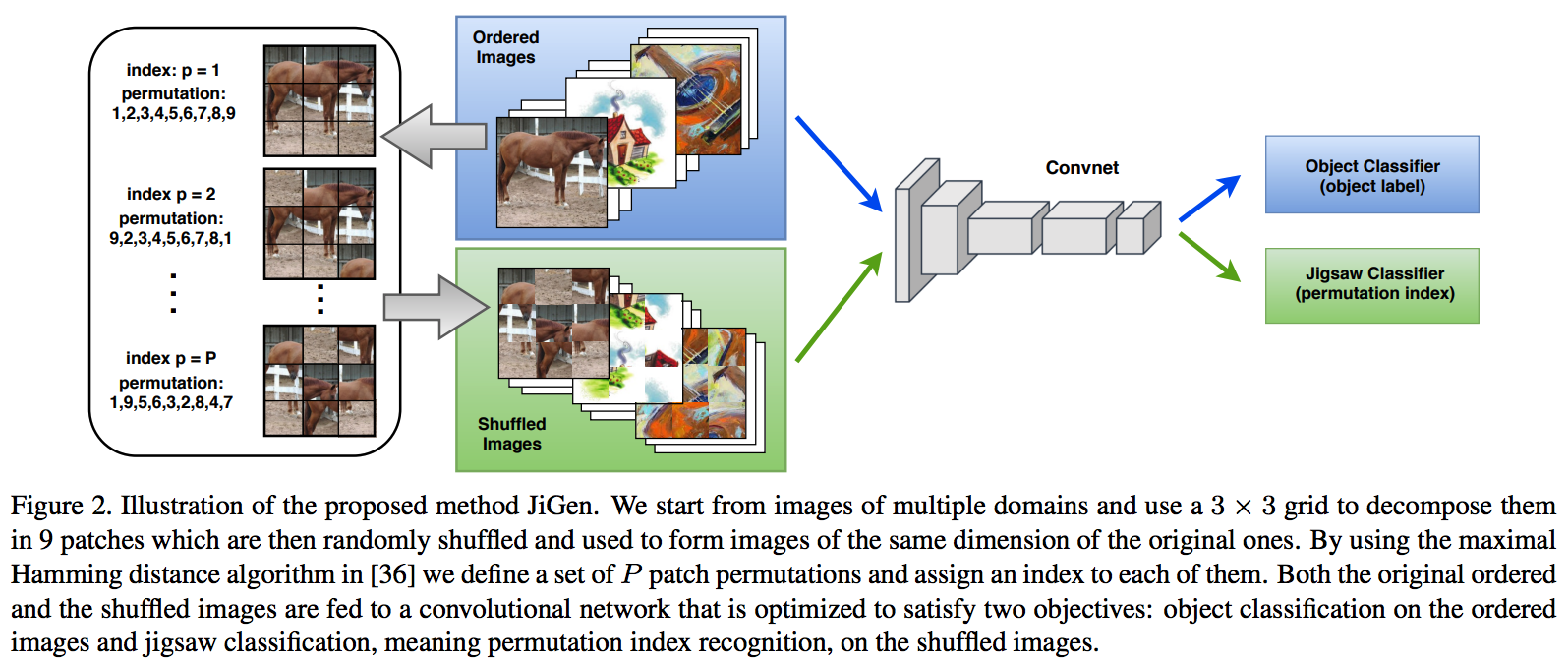 - `jigsaw puzzles task` 를 추가한 DG - Jigsaw puzzle task는 **(generalization을 위한/ overfitting을 막는) Network Regularizer** 역할을 한다. - Episodic Training 논문에서 주장하는 그당시 SOTA 논문이다. (개인적으로 Contrstive와 Classification을 동시에 하면 당연히 Generalization 성능이 좋아지는 거랑 같은 원리인듯 하다) - 그림 추가 설명 - 1~P 개의 permutation 중에서 하나를 골라 맞추면 되는 Jigsaw classifier task - Original ordered image 뿐만아니라 Shuffled Images 까지 Label Classication loss가 주어진다. # 2.14. WT: Iterative Normalization: Beyond Standardization towards Efficient Whitening -CVPR19 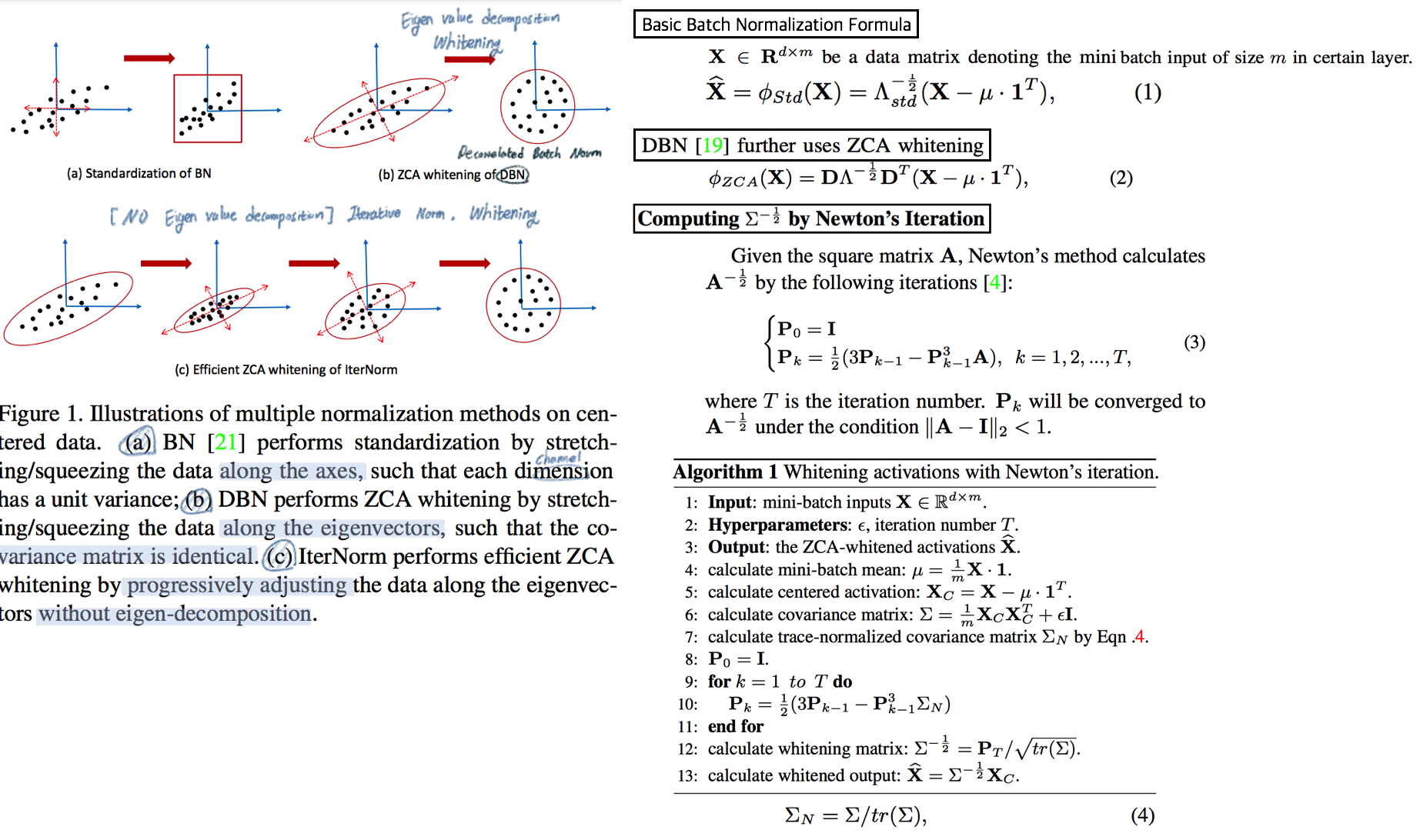 - RobustNet에 따르면, IBN-net보다는 성능이 낮고 SW(Switchable whitening) 보다는 성능이 좋은 WT Method - ( Stochastic Normalization Disturbance 개념을 소개하고 이용해서, 왜 group-wise whitening 이 좋았는지, BN에서 Batch size가 작으면 왜 성능이 떨어지는지 확인해본다. ) - DBN(Decorrelated Batch Norm)은 Eigen value decomposition을 한다는 문제점이 있었다. (Back-propagation는 DBN 논문에서 되도록 만들었지만, Computer Cost 문제는 어쩔 수 없었다.) - Whitening의 핵심 연산은 covariance matrix^(-1/2) 를 구하는 것이다. 이것을 구하기 위해 `Eigen value decomposition` 이 필수적이었다. 하지만, 이 논문에서는 `Newton’s iteration methods ` 를 사용해서 구하고자 한다. # 2.15. WT: Switchable whitening for deep representation learning -ICCV19 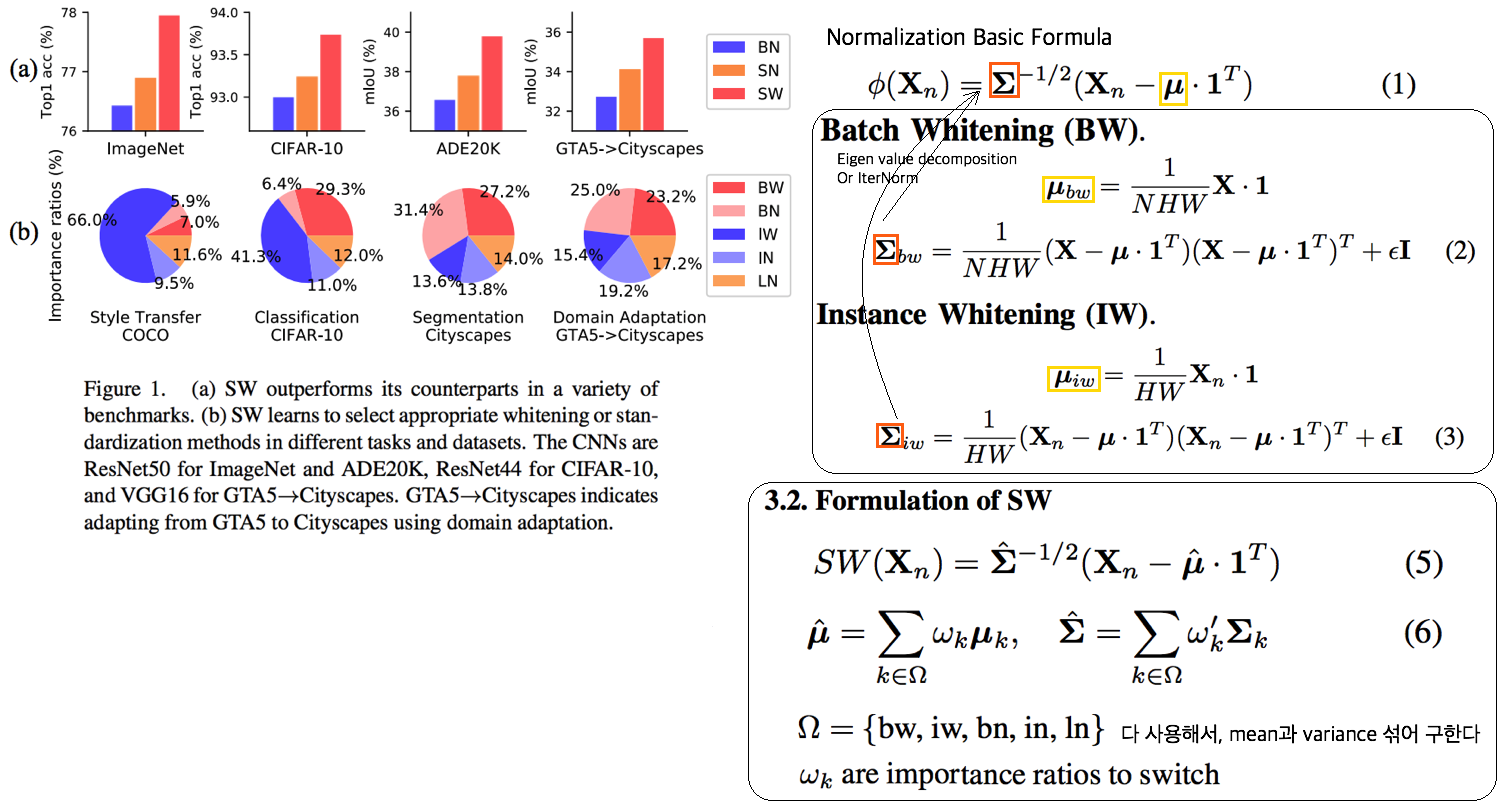 - RobustNet에 따르면, IBN-net과 Iter-Norm에 비해 Generalization 성능은 낮지만, 같은 Domain에서의 mIoU 성능유지는 가장 좋은 WT Method - BW(Batch Whiten) // IW(Instance Whiten) // BN // IN // LN(Layer Norm) // SN(Switchable Norm=왼쪽 3개의 Norm을 섞어 사용) // SW(Switchable Whiten=왼쪽 모든 Whiten, Norm 방법을 적절히 섞어 사용) - Switchable whitening 1. SW adaptively selects appropriate "whitening" or "standardization" statistics for different tasks 2. SW controls the ratio of each technique by learning their importance weights
# 2. RobustNet - Main Goal: Multi Source에 의지하지 않고, **Domain/ Appearance/ Weather/ Location/ Environment/ illumination/ Style Invariance 가진 모델 만들기!** 단, **'domain-specific style' and 'domain-invariant content' 를 분리하여, content에는 방해가지 않도록 한다.** - DNN에서 어떤 것이 Style 정보를 담고 있는가? Channel wise Correlation Matrix에 집중! (저자는 IBN-net에서는 IN이 DG를 위해 불충분하다며, Correlation을 고려하지 않았다고 했다. 하지만 내가 조사한 바에 따르면 Style에 관련된 요소는 더욱 많다. (DG survey post 1.14 참조) ) - Whitening Transformation 이란, **초기 Layer의 Feature map에 대해 채널 방향 공분산 행렬이 단위행렬이 되도록 만든 변환**이다. (==Feature map (CxHxW)를 [HW 백터 C개] 로 변환한 후, C개의 백터들에 대한 Covariance Matrix 를 Identity Matirx 형태가 되도록 하는 것이다.), 이렇게 하면 **이미지의 Style 정보가 제거 된다는 가설**이 있기 때문에, 이 논문에서는 WT를 적절히 적용하기 위한 노력들을 하고 있다. 1. Instance Whitening Loss (IW loss): Covariance Matrix **전체** == Identity Matrix 2. Margin-based relaxation of whitening loss (IRW loss): Covariance Matrix 전체 == Identity Matrix **+ ε (엡실론)** 3. Instance selective whitening loss (ISW loss): Covariance Matrix **일부 (domain-specific element position)** == Identity Matrix # 2.0 Relative work & Paper list  - **Multiple Source Domains** DG 논문들: Shared representation (general feature extractor) 학습하기. 1. 아래 과거 DG들의 문제점: 어쨋든 Multi Domain에 너무 많이 의지. Sources 갯수에 성능 변화 큼. 2. (#2.7) [29] Domain generalization with adversarial feature learning -CVPR18 3. (#2.10) (#2.10) [10] Domain generalization via model-agnostic learning of semantic features -NIPS19 4. (#2.6) [39] Unified deep supervised domain adaptation and generalization -ICCV17 5. (#1.8) [40] Domain generalization via invariant feature representation. -ICML13 6. (#1.9) [15] Domain generalization for object recognition with multi-task autoencoders -ICCV2015 7. (#2.5) [27] Learning to generalize: Meta-learning for domain generalization -arXiv17 8. (#2.8) [2] Metareg: Towards domain generalization using metaregularization -NIPS18 9. (#2.11) [28] Episodic training for domain generalization -ICCV19 10. (#2.12) [33] Feature-critic networks for heterogeneous domain generalization -ICML19 11. Generalizing Across Domains via Cross-Gradient Training -ICLR18 12. Generalizing to unseen domains via adversarial data augmentatio -NIPS18 13. (#2.13) Domain generalization by solving jigsaw puzzles -CVPR19 - **Sementic Segmentation DG** 1. [64] 2. [44] IBN net - **Correlation Matrix(CM)** 은 Image Style 정보를 담고 있다. 1. (#2.3) Texture synthesis using convolutional neural networks -NIPS15 2. (#2.4) Image style transfer using convolutional neural networks -CVPR16 (= A neural algorithm of artistic style) 3. domain adaptation [51, 57] 4. networks architecture [36, 45, 21, 56] - **channel-wise mean and variance** 이 담고있는 Style 정보를 이용하는 논문 [23], [25] (WT사용하는 [7]보다 성능 낮은) - **Whitening Transformation(WT)** 가 이미지의 Style 정보를 제거한다는 가설 1. (#2.2) Image-to-Image Translation via Group-wise Deep Whitening-and-Coloring Transformation -CVPR19 2. (#2.1) Universal Style Transfer via Feature Transforms -NIPS17 3. domain adaptation [45, 57, 51] 4. approximating the whitening transformation matrix using Newton’s iteration [22, 21] 5. WT의 단점1: diminish feature discrimination [45, 61] 6. WT의 단점2: distort the boundary of an object [31, 30] - **성능 비교 논문** 1. IBN net 2. Iterative normalization: Beyond standardization towards efficient whitening -CVPR19 # 2.1 WT&ST: Universal Style Transfer -NIPS17  - 기존 Style Transfer 모델들 문제점: Unseen style에 대한 generalizaing 능력과 visual quality가 부족하다. - Feature Covariance Matrix를 이용하는 (2가지 Feature transforms) `(1) whitening (2) coloring` 를 사용해서 이 문제를 해결하고자 한다. - WCT (Whitening and Coloring) 으로 최종 만들어진 Feature를 Reconstruction 해서 RGB 이미지를 만든다. 결과로 확인해 보면, WCT 이 HM(histogram matching) 을 사용한 것보다 Style 특성을 더 강렬하게 담아주는 것을 확인할 수 있었다. (= Covariance Matrix matching 이 HM 보다 더 강한 Style 정보를 전달해 주는가보다) - (Me: Recon된 결과를 보아하니, WT를 통해서 확실히 Feature에서 Style 정보를 제거해준다. (**Style이 아니라 Color정보를 지우는 것 뿐인가? Weather과 같이 Color 그 이상의 Style 정보를 지우러면 어떻게 해야할까?** --> **Weather-wise dataset을 가지고 각 Weather 마다 Deeplab을 fine-tuning을 한 후, Con, FC, Covariance, IN,BN 파라미터의 변화가 어디서 가장 많이 일어놨는지 확인해보면 되지 않을까??)** # 2.2 WT&ST: Image-to-Image Translation via Group-wise DWCT Transformation -CVPR19  - Motivation: MUNIT (Adaptive IN) 에다가, WCT (whitening and coloring Transform) 기법을 추가하면 어떨까?? Eigen value decomposion말고 Deep WT과 Deep CT를 적용한다. - (2.1) 논문의 내용을 베이스로 사용한다. WT과 CT를 Backpropa가 안되는 Eigen value decomposition을 사용하지 말고, Deep Learning 기법으로 사용해보자. 우선 DWCT 에 대해 아래와 같이 자세히 알기 전에, DWCT가 잘된다는 가정하에 위의 전체 아키텍처를 학습시켜서, Image Tranlation 모델을 만들어 낸다. - 위 사진의 오른쪽과 같이 Multi level (depth) 구조를 사용하는 이유는 논문에서 주장하는 이 가설 때문이다. (the low-level feature captures a local fine pattern, whereas the high-level one captures a complicated pattern across a wide area)  - GDWCT 를 하는 과정을 그림으로 표현했다. WT는 RobustNet에서 이미 잘 설명했다. 하지만 CT는 음.. 아직 잘 모르겠다. 수식을 봐도 잘 모르겠다. 근본적인 CT의 목표는 "Contents Feature 의 Covariance Matric == WCT Feature 의 Covariance Matirc" 로 만드는 것이다. 이것을 이와 같이 구현했다. 정도만 이해하자. # 2.3 ST: Texture synthesis using convolutional neural networks -NIPS15  - One spatial summary statistic: the **correlations** between feature responses in each layer of the network 을 직접 이용하는 첫 논문. 자세한 내용은 아래의 2.4 논문과 비슷하다. - 이 논문에서 Channel-wise Correlation matrix를 사용한 이유는 1. [2000년대 논문](https://link.springer.com/article/10.1023/A:1026553619983) 에서 Image Texture를 탐지하기 위해서, 이미지 자체의 Correlation 정보를 이용했었다. 2. Texture는 spatial information에 대해서 agnostic 해야하는데 Correlation이 이 조건을 만족한다. 다시 말해, 저자는 feature maps에서 the spatial information 를 제거하면서 Texture 정보를 담고 있을 만한 지표가 Correlation이라고 생각었나보다. # 2.4 ST: Image style transfer using convolutional neural networks -CVPR16   - Style Image 를 생성하는 방법은 하나의 Recon Network를 사용하는게 아니라, **Gradient를 직접 활용해 이미지를 생성**하는 아주 고전적인 방법이다. - 위 실험을 통해서 아래의 2개를 가정을 증명할 수 있다. - Content Loss를 적용하기 위해서는 Sauared-error loss (Euclidean Distance) 정도만 적용해도 무방하다. - Style(Texture) Loss는 Channel-wise Covariance Matrix를 사용한다. (Feature map의 channel == c 일때, c개의 채널 각각은 서로다른 필터(k x k x c_input) 에 의해 생성된 결과이라는 사실을 상기하자) # 2.9. MAML 먼저보기! # 2.5 DG: Learning to generalize: Meta-learning for domain generalization:MLDG -arXiv17  - `Meta Learning` 을 활용한 D. 그냥 Source domains 데이터를 그냥 한꺼번에 Supervised로 학습하지말고 (그냥 우걱우걱 학습하지 말고), Train-Test 과정을 시물레이션 함으로써 Network가 해당 시뮬레이션을 통해서 좀 더 옯바른 방향으로 학습되도록 유도한다. Loss를 1차적으로 거는게 아니라, 2차적으로 걸어준다. MetaTrain set에서 학습되는 Loss에 대해서, MetaTest set에서 학습되는 Loss를 추가적으로 걸어주는 방식이다. - [meta-learning method(이란?)](https://talkingaboutme.tistory.com/entry/DL-Meta-Learning-Learning-to-Learn-Fast) 을 적용한 첫 DG 모델이라고 할 수 있겠다. - a model agnostic training procedure(=미니배치 안에 가상 Target이미지 사용) 을 적용함으로써 train/test domain shift 를 시뮬레이션 할 수 있다. 아래의 알고리즘을 사용해서 모델을 학습시킨다. [코드로 공부](https://github.com/HAHA-DL/MLDG/blob/master/model.py#L312) `total_loss = meta_train_loss + meta_val_loss * flags.meta_val_beta` - S = 6 source domains into V = 2 meta-test and S − V = 4 meta-train domains. 데이터셋 분리는 다음과 같이 한다. - Why! 왜 이러한 작용이 Generalization에 도움을 줄까??? 그대로 전체 Data에 대한 Gradient를 주면, 한쪽 방향으로 쏠리고 Source Optimization이 일어난다. 중간중간에 Meta-dataset에 대한 Loss를 추가해줌으로써 One-dataset-overfitting-optimization 을 피하게 만들어 준다. # 2.6 DG: Unified deep supervised domain adaptation and generalization -ICCV17  - `Contrastive Learning`을 활용한 DG - Task: Supervised DA or DG in Classification. using Contrastive Loss - 만약 UDA를 한다면, (#1.3) MMD 기법으로 위 Equ(2) 를 적용한다. (p 는 softmax 정도로만 생각하자) # 2.7 DG: Domain generalization with adversarial feature learning -CVPR18  - `MMD regularizing Adversarial Learning` 을 활용한 DG 효과를 더욱 이끌어 낸다. - "모든 Domain을 고려하면, Hidden code는 결국 특정 분포(Ex.the Laplace distribution)를 따를 것이다" 라는 가정을 이용 - Total Loss 1. Reconstruction Loss: Hidden Code가 Input Image 로 reconstruction 잘 되었는가? (Contenct 유지 유도) 2. Classification Loss (Contenct 유지 유도) 3. Adversarial Loss: MMD에 의해서 generalization 성능은 높아질 수 있지만, 오직 Source domains에만 Overfitting 되는 것을 막아준다. Discriminator는 a prior distribution에서 나온 Sample 인지, Hidden code 인지 분별하는 역할을 하고, Discriminator가 혼동하도록, 즉 Hidden code가 a prior distribution에서 나온 값과 비슷하도록 유도해 준다. 여기서 prior distribution(=arbitrary distribution)은 **the Laplace distribution** 을 사용했다. Gaussian distribution and the Uniform distribution 를 사용하는 것보다 성능이 좋았다고 한다. (Generalization And Not-overfitting 유도) 4. [MMD Loss](https://github.com/YuqiCui/MMD_AAE/blob/master/utils/losses.py): 어떤 domain 이디든 Hidden Code가 비슷한 Embeding Space (공간)에 위치하도록 도와줌. (Generalization 유도) # 2.8. DG: Metareg: Towards domain generalization using metaregularization -NIPS18   - `meta regularization` 이라는 새로운 신경망을 사용한 DG. - MAML가 DA이지만, 우리는 DG이고, MLDG의 Generalization cost가 많이 필요하지만 우리는 Fixed F 를 사용해서 Cost 낮다. - Regularizer 라는 신경망을 먼저 이렇게 정의한다. "Generalization에 도움을 주는, Task Network가 하나의 Domain으로 학습될 때 overfitting 되지 않도록 규제해주는 역할을 하는 신경망" 처음에는 Φ(파이) 신경망을 무작정 사용하고, 이게 Iteration을 돌수록 점점 저런 역할을 하는 신경망이 될거라고 기대한다. (강화학습의 Policy, Q network 처럼.. 처음에는 아무 역할도 안하는 신경망이지만, 점점 원하는 역할을 하는 신경망이 되도록 유도한다.) - (**주의! 코드가 이상하니 신경쓰지 말기 // (#2.12) 내용과 거의 일치하다 **) novel regularization function in meta-learning framework: 아래의 순서로 Regularizer(nn.Linear( T network weight, 1))가 학습된다. [코드 확인](https://github.com/elliotbeck/MetaReg_PyTorch/blob/master/train.py#L148) Regularizer는 T network에 새로운 Loss를 줌으로써 T가 Generalization 되도록 도와주는 신경망이다. T network를 받고 Loss값이 스칼라값으로 나오는 신경망이다. 다시말해, **Generalization을 위해서 a domian을 학습하는 동안, "b와 c domain도 고려하니까 적당히 학습해!" 라는 느낌으로 beta 갱신에 사용된다** 1. ([Step1](https://github.com/elliotbeck/MetaReg_PyTorch/blob/master/train.py#L152)) Base model updates: 각 Domain data를 사용해서, 공통된 F 그리고 T1~Tp 모델을 학습시킨다. 2. Episode creating: 랜덤으로 2개의 domain을 선택해서, (1) metatrain set (`a` domain) (2) metatest set (`b` domain) 으로 설정한다. 3. ([Step2](https://github.com/elliotbeck/MetaReg_PyTorch/blob/master/train.py#L167)) Re-traing using metatrain set: 위 1번에서 학습되된 `a` domain 으로 파라미터로 Init한 F+Ta 모델을 `l` gradient steps 까지. `a` domain dataset으로 F+Ta를 학습시킨다. 4. ([Step3](https://github.com/elliotbeck/MetaReg_PyTorch/blob/master/train.py#L173)) Regularizer updates: model_regularizer는 input으로 T의 weight가 들어가고 output이 스칼라값이 나오는 nn.Linear 인데, 이 [스칼라값이 Loss로 동작](https://github.com/elliotbeck/MetaReg_PyTorch/blob/master/train.py#L186)해서 "Final F+T"를 update해준다. 신기하게도 model_regularizer는 `b` 이미지를 사용해 F+Ta 신경망에 의해서 계산 Loss값 backward 값으로 update된다. # 2.9. Meta: Model-Agnostic Meta-Learning for Fast Adaptation:MAML-ICML17  1. Tasks(Domains)를 사용해서, 어떤 Task에도 빠르게 adaptation 할 수 있는 pretrained-model 만들기를 목표로 한다. 2. The objective of the MAML approach is to find a good initialization θ such that few gradient steps from θ results in a good task specific network. (모델의 init weight(=Theta(보라색))를 적절하게 만드는 방법을 소개한다. 이 weight 는 새로운 Task에 init으로 사용해서 빠르게 적응/일반화 가능하다.) 3. 가장 아래 보라색 지점(theta)에서 파라미터 갱신을 하기 위해, 각 Task에 대해 학습한 결과인 빨간색 (theta')를 사용해서, 모든 Task에 적합한 파라미터의 지점 (연두색의 중간지점 쯤) 으로 Theta가 갱신되도록 유도하다. 4. 지금은 이해하기 힘들지만, 엄청 높은 Citation과 많은 논문에서 이 기법을 적용한다. 따라서 차근차근 이해하려고 노력해보자. [참고 유투브](https://www.youtube.com/watch?v=fxJXXKZb-ik) 5. PS. Few-shot-learning이란? N-way(Classes), K-shot(Samples) 총 NK개의 데이터만 사용해서 모델이 적절히 학습되게 만드는 알고리즘을 찾는 연구. 6. (#2.10 논문에서 차용) Intuitively, the training procedure/ is learning/ how to generalize/ under domain shift./ In other words, parameters/ are updated/ such that/ future updates with given source domains/ also improve/ the model/ regarding some generalizable aspects/ on unseen target domains. (직관적으로 이러한 학습 절차는 Domain shift를 고려한 generalization 이다. 다시말해서, 처음 파라미터 업데이트된 `theta'` 는 '미래의 파라미터 업데이트'를 위해서만 잠시 존재한다. '미래의 파라미터 업데이트'는 (Unseen target domains을 위한 Generalization 성능을 위해) `theta'` 와 MetaTest dataset을 활용해 구해진 gradient로 업데이트가 이뤄진다.) # 2.10. DG: Domain Generalization via Model-Agnostic Learning of Semantic Features -NIPS19  1. `MAML meta-learning`, `Contrastive Learning` 을 활용한 DG 2. 즉. a model-agnostic learning: (domain shift 를 시뮬레이션 하기 위해서) **meta-train and meta-test** procedures (to expose the optimization to domain shift. \|#D_train\| = 2 and \|#D_test\| = 1. 3. 궁극적 목표: **consistent features** 얻기 (:= Domain Invariance) 4. two complementary losses를 통해서 semantic features via global class alignment and local sample clustering 을 만들어 낸다. - `soft confusion matrix`: 각 Domain의 Class cluster 구조관계가 유사해야한다. - `metric-learning component`: Domain에 상관없이 같은 Class는 당기고 다른 Class는 밀어서, Class 마다의 Cluster를 가져야 한다. 5. Global Class Alignment Objective ([코드](https://github.com/biomedia-mira/masf/blob/master/utils.py#L107)) - MetaTrain_dataset에서의 각 Domain 각 Class 의 Centoids 위치가, MetaTest_dataset에서도 유사해야 한다. 즉 각 Domain 마다 Class centrois 위치는 비슷해야 한다. - (그림에서는 Covariance, Position simillarity 같이 생겼지만 아니다. ) 6. Local Sample Clustering Objective - 모든 Domain에 대해서 Class 별 Contrastive Loss # 2.11. DG: Episodic Training for Domain Generalization -ICCV19  - `Backprobagation` 의 흐름을 바꿔 학습시키는 DG - 현재 domain과는 정반대의 partner model과 상호작용하면서, Domain shift를 시뮬레이션 한 episodic로 Traning 진행했다. - Equ(5) 에서 ψ_r 은 Label space를 어떤 것을 가지든 상관없는 Classifier이다. 따라서 `heterogeneous domains generalization` 이 된 Feature Extractor (theta) 획득이 가능하다. - Figure 그림 추가 설명 - Figure1: Aggregation multi domain learning (AGG) 그냥 모든 Domain을 한꺼번에 묶어서 학습시킨다. - Figure2: N개의 Domain, N개의 모델 - Figure3: 하나의 AGG 모델을 두고, Figure2에서 Domain Sepecific Model을 가져와서 AGG의 Generalization 성능을 높힌다. - Figure4: 하나의 AGG 모델을 두고, heterogeneous DG Feature Extractor (Theta, Equ(5))를 학습시키고, 원하는 Classifier(ψ) 를 Equ(4)로 학습시킨다. # 2.12. DG: Feature-critic networks for heterogeneous domain generalization -ICML19  - 한 줄 정리: Regularizer Network으로써, Feature-critic Network를 사용한다. - Feature-critic Network 1. "현재의 Feature Extractor 파라미터가, MetaTest-domain의 성능일 올려줄지 아닐지"를 예측해주는 네트워크이다. 2. 이 Network를 사용해 Train 과정에서 Ausilliary loss를 뽑아내고, Validation 과정에서 이 Network를 update한다. 1. Equation 설명 1. Equ (2): 전체 Classification 모델을 학습시키는데 사용할 Loss 2. Equ (6), (7): 다양한 종류의 h(w) = Feature-critic Network 3. Equ (3): h(w)의 parameter인 w가 가져야할 조건. (Meta_test Domain에서 더 좋은 결과를 가지도록 Loss를 유도해 줘야 함) 4. Euq (5): h(w)를 optimize 하기 위해서, 사용하는 h(w) Loss function. Old theta보다 New theta에 의해서 Validation 이미지의 예측결과가 더 좋아지도록 유도하면서, 동시에 Ausilliary loss에 의해서 새롭개 갱신된, New theta가 generalization 능력을 갖춘 theta가 되도록 유도한다. # 2.13. DG: Domain Generalization by Solving Jigsaw Puzzles -CVPR19  - `jigsaw puzzles task` 를 추가한 DG - Jigsaw puzzle task는 **(generalization을 위한/ overfitting을 막는) Network Regularizer** 역할을 한다. - Episodic Training 논문에서 주장하는 그당시 SOTA 논문이다. (개인적으로 Contrstive와 Classification을 동시에 하면 당연히 Generalization 성능이 좋아지는 거랑 같은 원리인듯 하다) - 그림 추가 설명 - 1~P 개의 permutation 중에서 하나를 골라 맞추면 되는 Jigsaw classifier task - Original ordered image 뿐만아니라 Shuffled Images 까지 Label Classication loss가 주어진다. # 2.14. WT: Iterative Normalization: Beyond Standardization towards Efficient Whitening -CVPR19  - RobustNet에 따르면, IBN-net보다는 성능이 낮고 SW(Switchable whitening) 보다는 성능이 좋은 WT Method - ( Stochastic Normalization Disturbance 개념을 소개하고 이용해서, 왜 group-wise whitening 이 좋았는지, BN에서 Batch size가 작으면 왜 성능이 떨어지는지 확인해본다. ) - DBN(Decorrelated Batch Norm)은 Eigen value decomposition을 한다는 문제점이 있었다. (Back-propagation는 DBN 논문에서 되도록 만들었지만, Computer Cost 문제는 어쩔 수 없었다.) - Whitening의 핵심 연산은 covariance matrix^(-1/2) 를 구하는 것이다. 이것을 구하기 위해 `Eigen value decomposition` 이 필수적이었다. 하지만, 이 논문에서는 `Newton’s iteration methods ` 를 사용해서 구하고자 한다. # 2.15. WT: Switchable whitening for deep representation learning -ICCV19  - RobustNet에 따르면, IBN-net과 Iter-Norm에 비해 Generalization 성능은 낮지만, 같은 Domain에서의 mIoU 성능유지는 가장 좋은 WT Method - BW(Batch Whiten) // IW(Instance Whiten) // BN // IN // LN(Layer Norm) // SN(Switchable Norm=왼쪽 3개의 Norm을 섞어 사용) // SW(Switchable Whiten=왼쪽 모든 Whiten, Norm 방법을 적절히 섞어 사용) - Switchable whitening 1. SW adaptively selects appropriate "whitening" or "standardization" statistics for different tasks 2. SW controls the ratio of each technique by learning their importance weights
