【DG】 Survey DG papers 1 - IBN-net and Relative 14 papers
 --- --- # 1. IBN-net -ECCV18 - IN(`Instance Normalization`)과 BN(`Batch Normalization`)에 대한 깊은 탐구와 적절한 사용을 한다. ([IN, BN 수학수식 참조](https://becominghuman.ai/all-about-normalization-6ea79e70894b)) - `Main Issue`: the appearance gap - 해결방법1: Finetunning ->> trivial solution - 해결방법2: appearance invariance를 Feauture가 배우도록 유도하기 - Max pooling, deformable conv ->> spatial invariance 일뿐. - Appearance invariance == The invariance of arbitrary image styles and virtuality (reality) - IBN-Net만의 특장점, 차이점 1. combining IN (Sample variance에 영향 적음) and BN (recognition 성능 향상) 2. IN과 BN의 적절한 사용
--- --- # 1. IBN-net -ECCV18 - IN(`Instance Normalization`)과 BN(`Batch Normalization`)에 대한 깊은 탐구와 적절한 사용을 한다. ([IN, BN 수학수식 참조](https://becominghuman.ai/all-about-normalization-6ea79e70894b)) - `Main Issue`: the appearance gap - 해결방법1: Finetunning ->> trivial solution - 해결방법2: appearance invariance를 Feauture가 배우도록 유도하기 - Max pooling, deformable conv ->> spatial invariance 일뿐. - Appearance invariance == The invariance of arbitrary image styles and virtuality (reality) - IBN-Net만의 특장점, 차이점 1. combining IN (Sample variance에 영향 적음) and BN (recognition 성능 향상) 2. IN과 BN의 적절한 사용 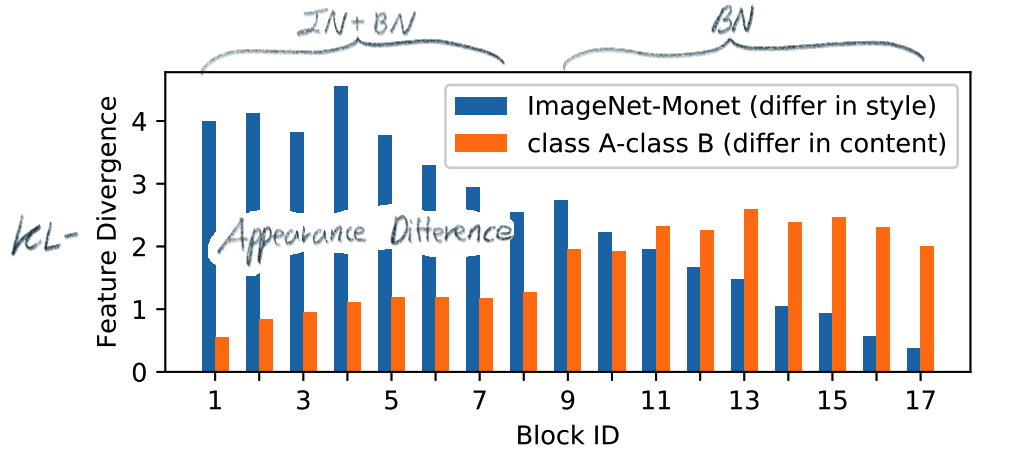 - Contributions 1. Style Transform의 IN을 사용해서, distorted ImageNet에 대해서 SOTA 2. 실험을 통한 IN과 BN 분석 1. `IN`: visual and appearance invariance BUT> drops useful content information 2. `BN`: Feature와 individual samples 간의 차이를 줄여서, 학습 수렴을 가속화. BUT> Appearnce 변화에 약한 CNN 탄생 - Relative Works 1. Domain Adapataion 을 위해서 사용하던 기법들 (하지만 이것도 결국 Target Domain에 의지함) - MMD(maximum mean discrepancy) - CORAL(correlation (covariance) allignment) - AdaBN - GAN - Adversarial Loss - Pseudo Label Generation 2. Domain Generalization 과거 기법들 [아래 논문들 참조] - `domain agnostic representations` 을 학습하거나 `모든 domains에 대한 공통점`을 학습하려고 노력함 - 하지만 이 방법들도 Source domain datasets (:= related source domains) 에 많이 의존한다. 3. IBN 논문에서는 / **앞으로 DG를 위해 내가 생각해야할 포인트**는 1. **DA처럼 Target에 의존하지 않고, 이전 DG처럼 Sources에 의존하지 않는 Generalization 기법을 찾고자 한다.** (DG가 Source에 의존하지 않는 것은 불가능하다. 하지만 최대한 의존하지 않으면서 모델을 학습시키고자 노력한다.) 2. IN와 같이 **appearance invariance 성질을 가진 Layer 를 찾아** 모델에 넣었다. - Method 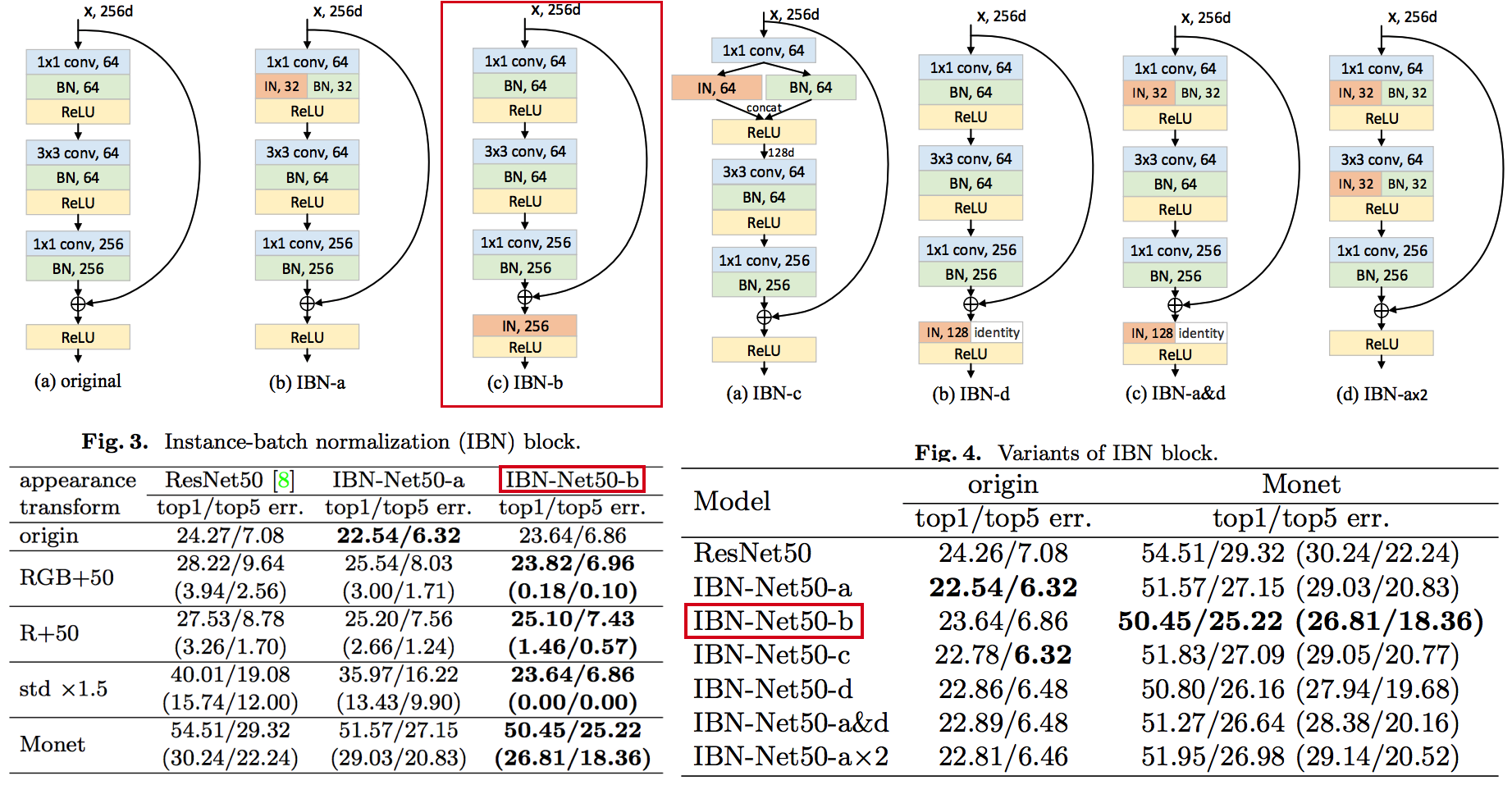 # 1.1 **읽어야할 다음 논문 List** 1. IN을 사용해서 individual contrast를 제거함으로써 Style transfer를 수행하는 논문들 - (#NO 핵심이 없고 메소드도 명확하지 않고 이해가 안된다) Improved texture networks: Maximizing quality and diversity in feed-forward stylization and texture synthesis. CVPR (2017) - (#13) A learned representation for artistic style. ICLR (2017) - (#14) Arbitrary style transfer in real-time with adaptive instance normalization. ICCV (2017) 2. 다양한 Adpatation 기법들 - (#2) AdaBN: Adaptive Batch Normalization - MMD: (#3) Deep Domain Confusion: Maximizing for Domain Invariance, (#4) Learning Transferable Features with Deep Adaptation Networks - CORAL: (#5) Deep coral- correlation (covariance) alignment for deep domain adaptation 3. DG 논문들 - (#7) Undoing the damage of dataset bias. ECCV (2012) - (#8) Domain generalization via invariant feature representation. ICML (2013) - (#9) Domain generalization for object recognition with multi-task autoencoders. ICCV (2015) 4. 참고사항!! - feature correlations matrix := covariance matrix := feature dot similarity := a gram matrix - Instacne Normalization을 해주고 feature dot similarity matrix == correlations matrix - 헷갈리지만, 다 비슷비슷하다. 코드를 보면서 필요한 것을 사용하자. # 1.2. DA: AdaBN -arXiv16 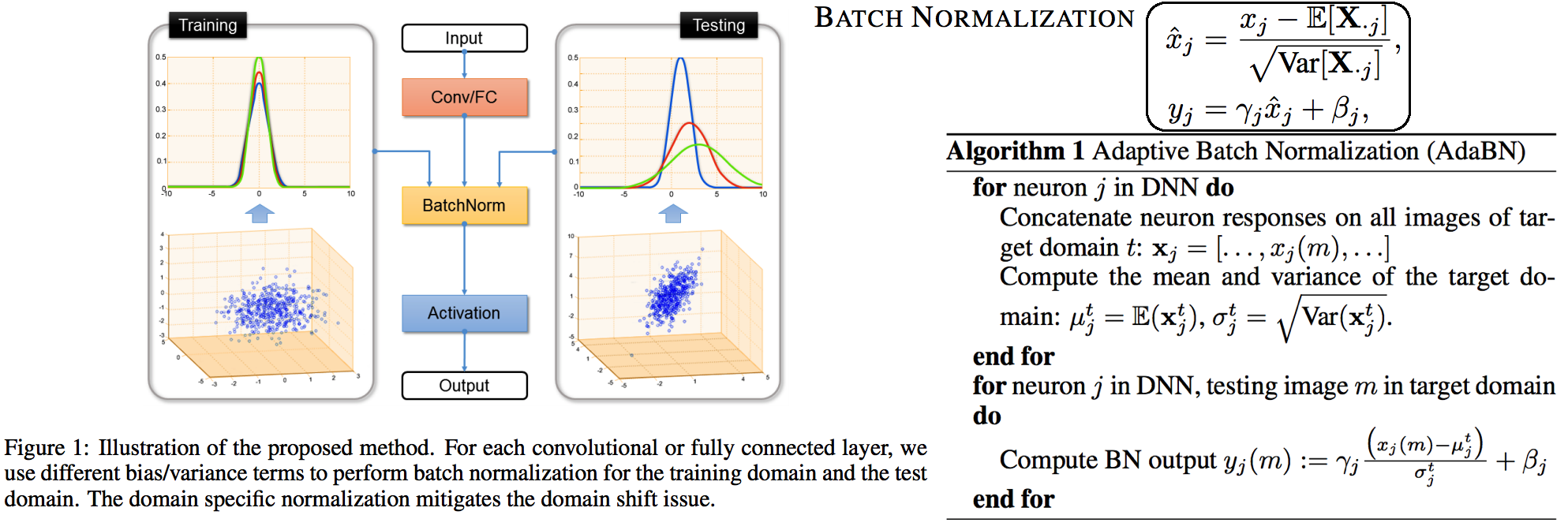 - "Label(Contents) 와 관련된 내용은 Conv/FC의 weight에 저장되어 있고, Domain 에 관련된 내용은 BN에 저장되어 있다는 가설"을 제시한다. - 새로운 Domain Dataset에 대해 위 알고리즘 방법을 사용해서 BN mean, standard diviation를 바꿔, 모델 Transfer를 진행한다. - 이미 학습된 γ (감마) and β (배타) 에는 이미 Source 의 Style이 남아있으니... mean, standard diviation 이라도!! Target **전체** 이미지의 평균, 표준편차값을 이용하여 Target domain에 그나마 적절한 BN을 수행하겠다. - (Me: Conv/FC의 weight에 Invariance 성질을 어떻게 넣을까??) # 1.3. DA: Maximizing for Domain Invariance -arXiv14 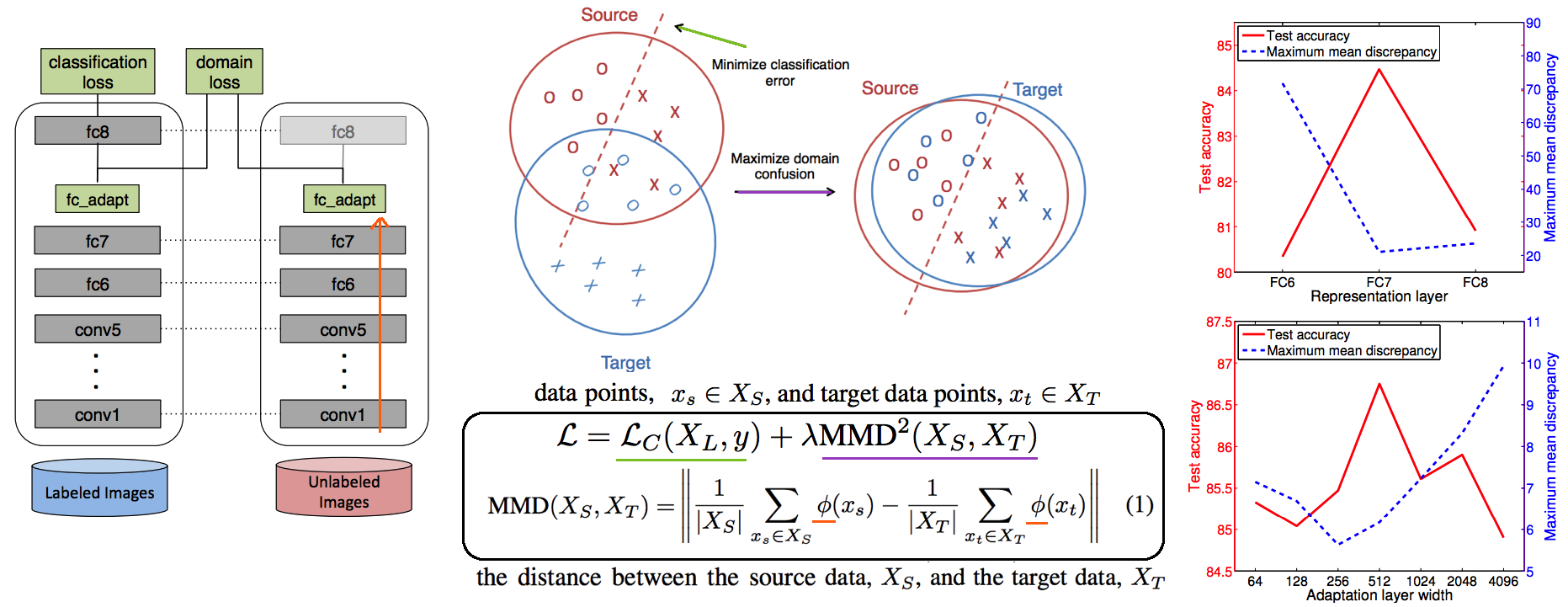 - `Additional domain confusion Loss` == `domain confusion metric` == `MMD` - 이미지 feature 각각의 (1대1 매칭) 거리 비교는 아니고, 데이터셋 전체의 Feature Centroids를 비교해서 domain confusion을 구한다. 이미지 아래 수식 참조. - domain confusion 이 최소화 되도록 Model 에 Loss를 준다. 또한 domain confusion 계산값을 이용해 feature를 뽑아야하는 layer와 fc-dimmension을 설정한다. # 1.4. DA: MK-MMD -ICML15 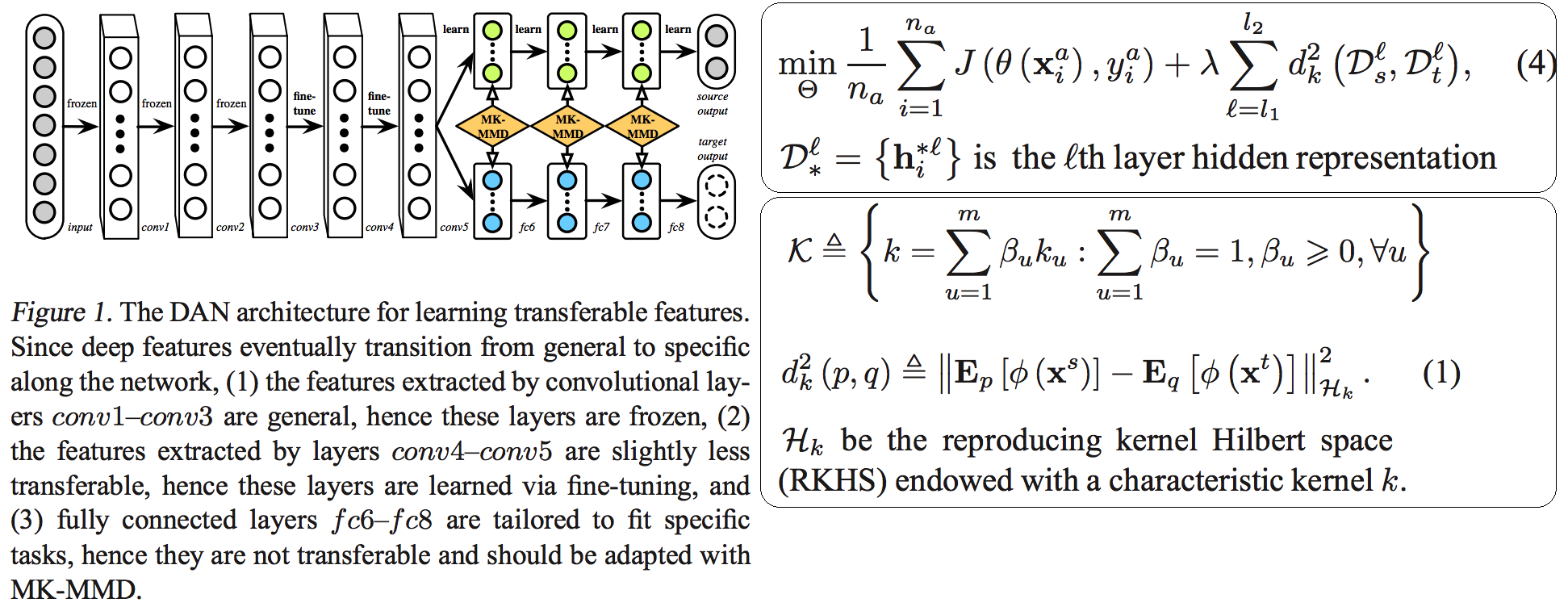 Paper: Learning Transferable Features with Deep Adaptation Networks - Deep Adaptation Network (DAN) - [reproducing kernel Hilbert space](https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=sw4r&logNo=221491666976) (RKHS) 개념을 사용해서, 기존의 MMD를 multiple kernel variant of MMD (MK-MMD) 으로 바꿔 사용 - Feature map 그대로에 대한 Distance를 비교하는 것이 아니라, Feature에 특정한 kernal (다양한 종류의 행렬변환/ 비선형 변환등 모두 가능) 을 적용해 새로운 Feature를 만들고 그것에 대해서 Distance를 비교한다. 이때 Kernel은 [PSD kernal](https://en.wikipedia.org/wiki/Positive-definite_kernel)을 사용한다고 한다, ->> 딥한 수학적 내용이어서 이해는 이정도만 하자. - 위의 수학 수식과 개념은 복잡해도, 코드를 확인해보면 별거 없다. Source와 Target Feature에 Gaussian_kernel을 적용하고 두개의 Distance를 비교하는듯 하다. [MK-MMD](https://github.com/ZhaoZhibin/UDTL/blob/master/loss/DAN.py) # 1.5. UDA: Correlation alignment -ECCV16 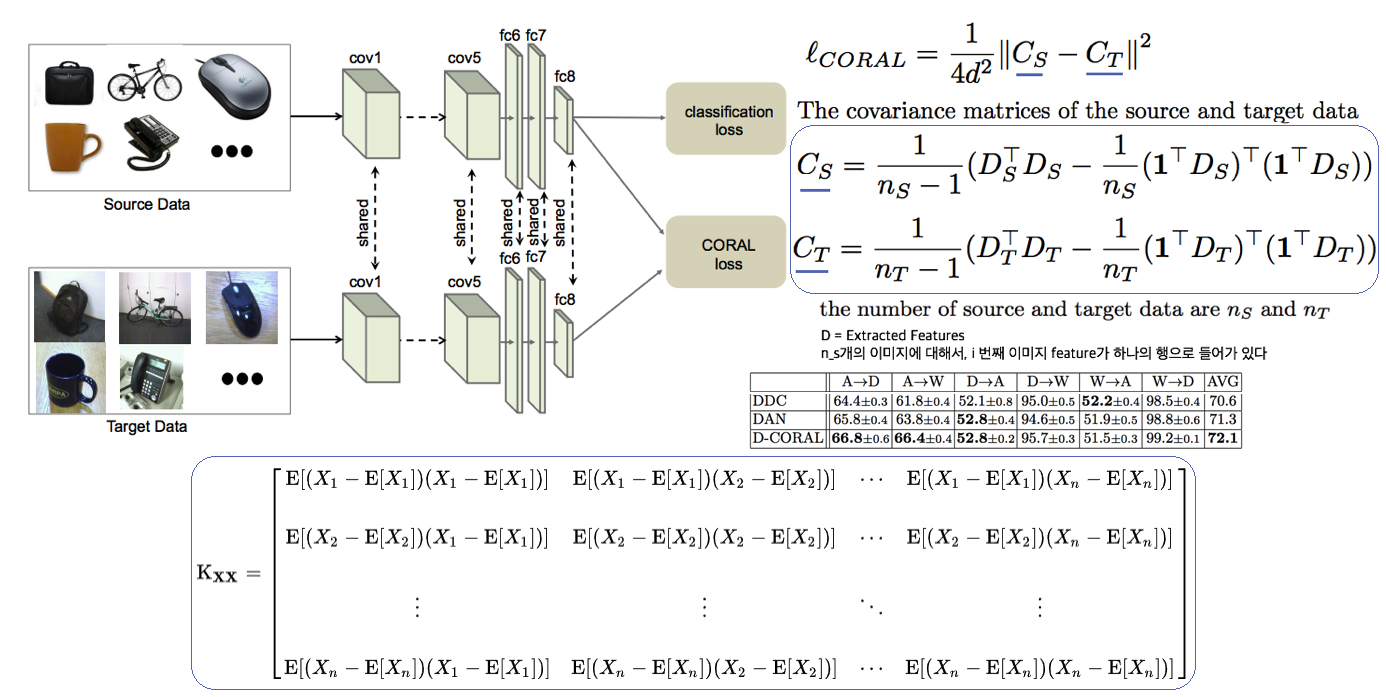 - [CORAL Loss 코드 링크](https://github.com/ZhaoZhibin/UDTL/blob/master/loss/CORAL.py) ([frustratingly easy domain adaptation](https://arxiv.org/pdf/0907.1815.pdf) - 2009): "각 Domain의 Feature들 사이의 공분산" 차이를 최소화하여, UDA 하고자 한다. 위 이미지에서 [위 파란색 박스 공분산 수식] 보다는 [아래 파란색 박스 공분산 수식]을 보고 코드와 비교해서 이해하도록 하자. 아래 공분산 수식에서 X_k 가 k번째 이미지의 Feature를 의미한다. - 주의!!! 이것말고 아래 논문들이 CORAL은 Channel-wise 이다. 이 논문에서는 1 Image 1 vector (N images M dim vector) NxM matrix 를 이용한다. - MMD(1.3) 기법과 유사한 방법이지만, MMD에서는 `Feature들의 평균`을 비교했다면, 이 논문에서는 `Feature들의 공분산` 을 비교한다. MMD(1.3=DDC)기법보다는 강력하고 MK-MMD(1.4=DAN)기법보다는 심플한 방법이다. - (이 이후에, AdaptSeg, ADVENT가 나오면서 Adversarial Learning을 기법을 이용한 Adaptation 기법들이 주를 이루기 시작했다.) # 1.6. UDA: by Backpropagation -14 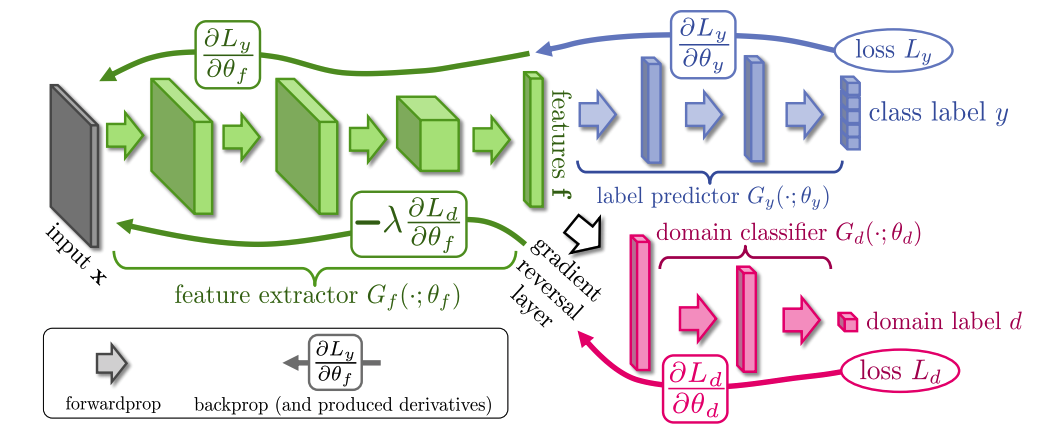 - gradient reversal layer 가 핵심이다. 기존 Gradient 에 -1 을 곱해서 반대 Gradient를 준다. - AdaptSeg와 Advent 같은 Adversarial learning 과 비슷하면서도 다른 방법이다. Network에 혼란을 주겠다는 같은 목적을 가지고 있지만, Adversarial 처럼 직관적이고 정확한 gradient를 주기에는 무리가 있는 고전방법이다. # 1.7. DG: Undoing dataset bias -ECCV12 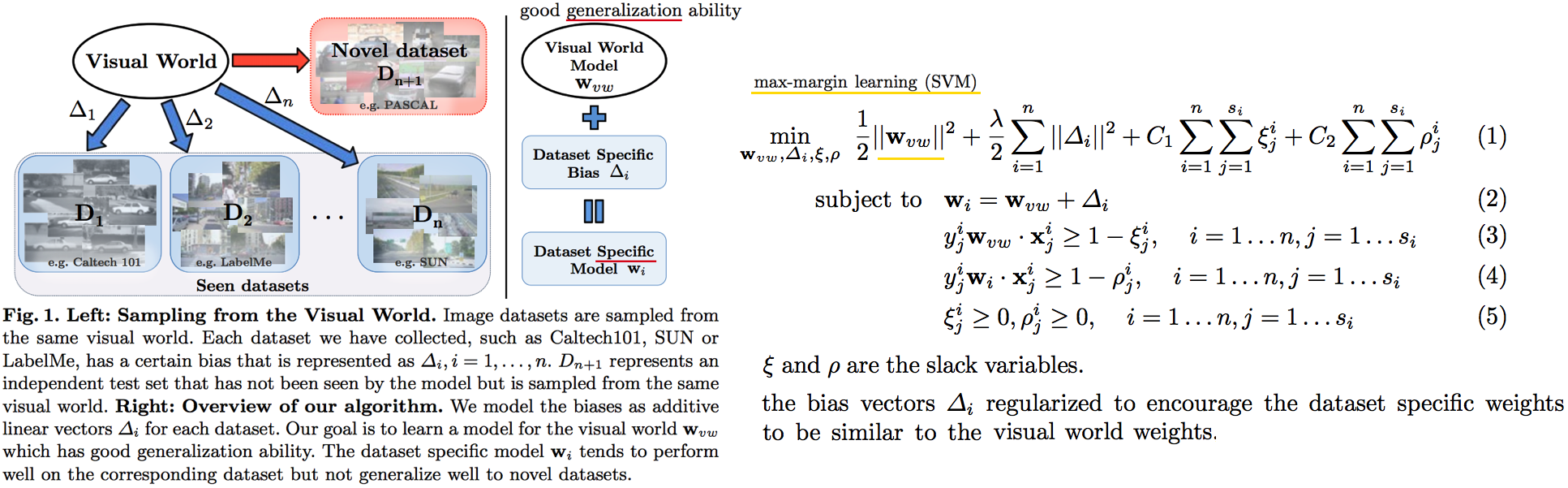 - SVM과 Visual world 관점에서 Optimization이 이뤄지기 때문에, CNN과는 다른 관점으로 이해할 필요가 있다. (이 방법론을 차라리 CNN weight로 바꿔 생각해보자. 이해가 더 쉽다.) - 모델을 통해서 학습하고자 하는 것은 2가지 이다. (1) `bias vectors` (2) `visual world weights(=모든 데이터셋을 위한 Main Model)` - 핵심: Dataset에 대한 Bias를 인정하고, 한 Dataset에 특화된 모델(w_i)에서 (1) Bias 성질과 (2) General model W_vw 를 분리해내고자 노력한다. 즉 `모든 Source domains에 대한 공통 weights` 을 학습하고자 노력한다. - IBN-net, RobustNet 관점에서 **Appearnce invariance 성질을 가진 Feature/Model/Weight를 학습하고자 하는 노력**은 동일하다. 하지만 Source datasets에 너무 많이 의존한다는 단점을 가진 과거 기법이다. # 1.8. DG: via invariant feature representation -ICML13 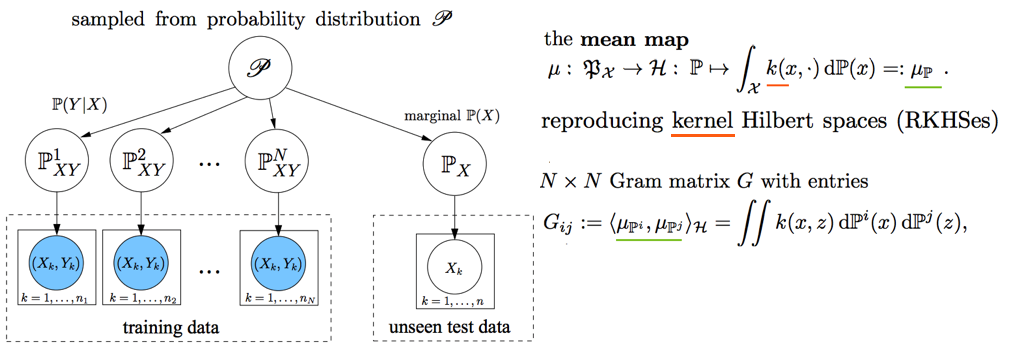 - 이 논문은 (1.4) MK-MMD 에서 Deep Learning 기법이 아닌 고전적인 기법을 사용한 논문이라 이해하면 된다. 또한 MMD는 Source와 Traget을 이용해서 Adaptation 을 수행한다면, 이 논문에서는 Multi-sources 를 사용해서 Multi-Adaptation 모델을 만든다. 이 논문의 저자들은 이것을 Generalization이 이뤄진 것이라 주장한다. 하지만 지금 관점에서는 `domain agnostic representations in terms of ONLY Source domains` 을 학습한다고 느껴진다. - MMD 처럼 어떤 Source Domain의 이미지가 Input으로 들어가든, **Output 값의 평균이 비슷하도록 만든다. 즉 적절한 Kernel을 만들어(학습시켜) G가 Zero가 되도록 만든다.** - Paper key sentences 1. Domain-Invariant Component Analysis (DICA) extracts invariants 2. **minimizing the dissimilarity across domains** 3. preserving the functional relationship between input and output variables 4. Using dimension reduction algorithms including kernel principal component analysis (KPCA) # 1.9. DG: with multi-task autoencoders -ICCV15 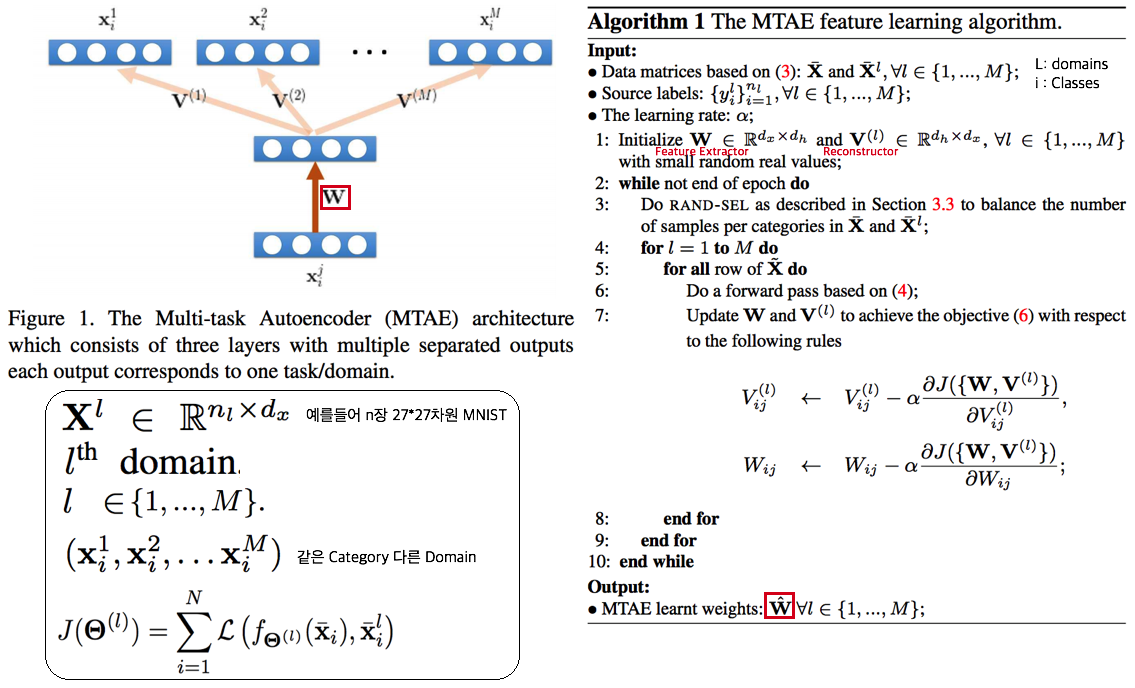 - 같은 Class, 다른 Domain의 이미지를 Reconstruction하는 Task를 (서로 다른 Domain에 대해서) Multi로 수행하여 Weight가 Domian General하게 만든다 - 위와 같은 알고리즘으로 만든 W는 Image classification을 위해서 사용된다. - Domain Generalization이라고 하지만, Multi-sources를 활용한 Self-supervised Learning 기법이라고 하는게 맞겠다. 저자는 이 아이디어가 domain invariance에 유용한 Backbone을 만들 수 있을거라 주장한다. 하지만 이 아이디어를 Contrastive Learning과 비교한다면, Contrastive Learning 기법으로 만든 Self-sup-weight 만으로도 충분히 Generalization에 도움이 더 될 것 같다. - Paper key sentences 1. Multi-Task Autoencoder (MTAE) provides good generalization performance. 2. MTAE learns to transform the original image into analogs "in multiple related domains" 3. jointly learns multiple data-reconstruction tasks # 1.11. ST: Perceptual Losses for Real-Time Style Transfer -arXiv16  - Style Transformer의 시작, 유명한 저자(Justin Johnson, Alexandre Alahi, Li Fei-Fei), [RobustNet correlation (covariance) Matric 계산그림](https://junha1125.github.io/blog/artificial-intelligence/2021-05-22-RobustNet/#41-iw-loss-instance-whitening-loss), dot_similarity != correlation (covariance) 서로 다르니 주의하자. - Feature Reconstruction Loss - Euclidean distance, Contenct 를 유지하도록 만든다. - Higer layers 에서 Loss를 적용하기 때문에, `Content and overall spatial structure` 는 보존하면서 `color, texture` 는 따라하지 않도록 만든다. - Style Reconstruction Loss - `style: colors, textures, common patterns` 만을 따라하도록 만든다. - Gram matrices(=Channel Wise dot_similarity matrices)의 Frobenius norm (L2-norm) 차이(로스)가 작아지도록 유도한다. - [Gram matrices 계산 코드](https://github.com/dxyang/StyleTransfer/blob/master/utils.py#L22) - Style Loss를 처음 제안한 논문 (아래 논문을 통해서 RobustNet에서 주장한 "**correlation (covariance) Matrix가 Style 정보를 담고 있다**"라는 가설에 대해 분석해볼 수 있겠다) - (DG survey2 참조) Texture synthesis using convolutional neural networks - (DG survey2 참조) A neural algorithm of artistic style # 1.12. ST: Instance Normalization -arXiv16 - Paper: [Instance Normalization: The Missing Ingredient for Fast Stylization](https://arxiv.org/pdf/1607.08022.pdf) - 바로 위 논문과는 조금 다른 형태의 Generator를 가지며 비슷한 시기에 나온 [Style transform 논문](https://arxiv.org/pdf/1603.03417.pdf). 심플하게 이 안에서 BN들을 IN으로 바꿨다. - Style Transfer의 기본 모델들은 ImageNet으로 Pretrained 된 network를 사용했다. 그래서 BN을 그대로 사용한다. - IN를 사용함으로써, Sample/Image/Instance에 특화된 Feature를 유지하게 해주어, 더 좋은 Style Transform이 가능하게 한다. # 1.13. ST: Learned Representation For Artistic Style -ICLR17 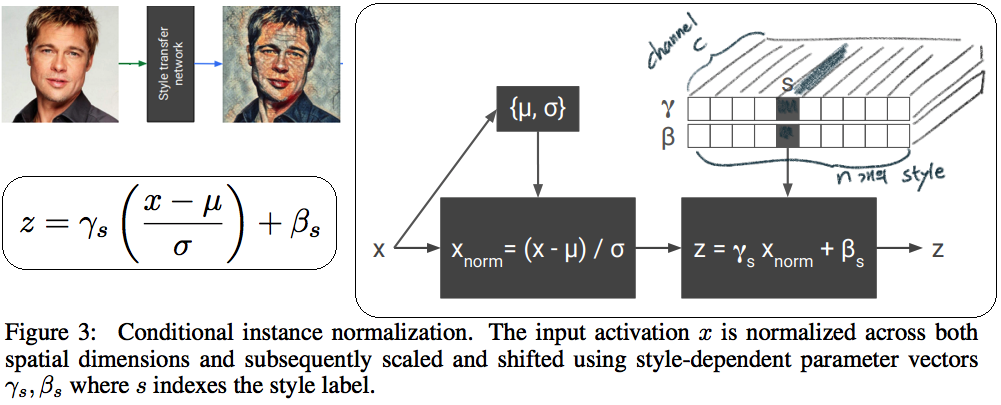  - 이용할 만한 핵심 내용 - **Style Transfer Network 에서, Style에 영향을 주는 파라미터는 γ (감마) and β (배타) 이다.** 그 외 Conv layer의 파라미터는 거의 영향을 미치지 않는다. - 따라서 영향이 적은 파라미터는 완전히 고정시키고, 스타일 마다 다른 γ (감마) and β (배타) 를 학습시키고, γ (감마) and β (배타) 를 다르게 설정하는 것 만으로, 놀랍게도 다른 스타일의 이미지를 쉽게 생성할 수 있다. - 논문 내용 정리 1. (1.11) Old style transfer 모델은 하나의 transfer network가 하나의 스타일만 만들 수 있는 `single-purpose nature` 문제점이 존재했다. 이 논문은 이러한 문제를 해결하고자 한다. 각 스타일을 만드는 모델들이 비슷한 파라미터 값을 가지는 것이 확인하고 연구가 시작되었다. 2. 원하는 Style을 조건적으로 선택하여 하나의 Style Tansfer가 N개의 Style을 생성할 수 있는 Network를 만든다.( `conditional style transfer network`) 선택적으로 감마와 베타를 고르는 작업을 `conditional instance normalization` 이라고 표현한다. 3. 새로운 Style에 대한 Style transfer network를 만들고 싶다면, conv와 같은 Layer는 놔두고 γ (감마) and β (배타) 만 학습시키면 되니, 학습도 매우 빠르게 가능하다. # 1.14. ST: Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization -ICCV17  이 논문의 핵심은 위 (1.13)과 동일하다. (1.13) 과의 핵심 차이점은 (learnable parameter) γ (감마) and β (배타) 를 ->> (No learnable parameter) standard_deviation( y ), Mean( y ) 로 바꾼것이다. 하지만 이 논문이 해석과 분석을 완벽하게 하였다. 그래서 내가 "왜 IN을 통해서 저런 효과를 얻을 수 있는지" 이해할 수 있었다. 매우 좋은 논문이었다. 따라서 정리를 좀 더 완벽하게 할 계획이다. - 문제점과 해결: 지금까지 Style Transfer 기법들은 1개 혹은 N개의 제한된 Style만을 변환할 수 있는 모델들이었다. 이 논문 기법을 통해서 어떤 Style의 이미지가 들어와도 Style Transfer를 수행할 수 있는 모델을 만들었다. `adaptive instance normalization (AdaIN) layer` 가 핵심이다. - `Contents Loss`는 Euclidean distance를 그대로 사용한다. 하지만 `Style Loss`는 아래와 같이 다양한 Loss가 있다. 이렇게 다양한 Loss를 통해서, 나는 `Deep Network에서 Style 정보를 담고 있는 부분`을 정리&분석해 볼 수 있었다. 1. 다양한 종류의 `Style Loss`: MRF loss [30], adversarial loss [31], histogram loss [54], **CORAL loss** [41], MMD loss [33], and **distance between channel-wise mean and variance** [33]. 특히 이 논문에서 사용하는 Loss는 [Distance between channel-wise mean and variance loss (코드링크)](https://github.com/naoto0804/pytorch-AdaIN/blob/master/net.py#L130) 이다. 하지만 Gram matrix 를 사용해도 비슷한 성능이 나왔다고 한다. (따라서 Distance 와 gram 은 Style 정보를 비슷하게 가지고 있겠구나!) 2. `Deep Network에서 Style 정보를 담고 있는 부분` (내가 이용할 만한 내용 분석) 1. IN 의 파라미터 값 2. Channel-wise dot_similarity Matrix = [Gram matrices](https://github.com/dxyang/StyleTransfer/blob/master/utils.py#L22) 3. Channel-wise correlation (covariance) Matrix (in [CORAL](https://github.com/ZhaoZhibin/UDTL/blob/master/loss/CORAL.py), RobustNet) 4. Channel-wise mean and variance - `이 논문이 IN에 대해 분석한 핵심` 1. "IN은 Feature를 Normalization함으로써 일종의 `style normalization` 을 수행한다. 즉, 어떤 Style이 들어와도 Normalize하여 (적절한 위치로 이동시키는 것을 도와주어), Network가 빨리 수렴되고 Style Invariance 를 가지게 도와준다. 2. 반대로 BN은 한 Batch의 이미지를 하나의 Style로 Normalize 해버린다. 그래서 Style Transfer Network가 학습되는 동안 Batch 속 이미지 각각이 자신의 Content와 Style을 유지하는데 방해를 주어, 학습 수렴이 잘 안되게 만든다. 3. 논문의 Figure1을 통해서 IN의 성질에 대해 증명하였다. (증명과 실험 내용은 필요하면 참고. 핵심만 적어 놓는다)
- Contributions 1. Style Transform의 IN을 사용해서, distorted ImageNet에 대해서 SOTA 2. 실험을 통한 IN과 BN 분석 1. `IN`: visual and appearance invariance BUT> drops useful content information 2. `BN`: Feature와 individual samples 간의 차이를 줄여서, 학습 수렴을 가속화. BUT> Appearnce 변화에 약한 CNN 탄생 - Relative Works 1. Domain Adapataion 을 위해서 사용하던 기법들 (하지만 이것도 결국 Target Domain에 의지함) - MMD(maximum mean discrepancy) - CORAL(correlation (covariance) allignment) - AdaBN - GAN - Adversarial Loss - Pseudo Label Generation 2. Domain Generalization 과거 기법들 [아래 논문들 참조] - `domain agnostic representations` 을 학습하거나 `모든 domains에 대한 공통점`을 학습하려고 노력함 - 하지만 이 방법들도 Source domain datasets (:= related source domains) 에 많이 의존한다. 3. IBN 논문에서는 / **앞으로 DG를 위해 내가 생각해야할 포인트**는 1. **DA처럼 Target에 의존하지 않고, 이전 DG처럼 Sources에 의존하지 않는 Generalization 기법을 찾고자 한다.** (DG가 Source에 의존하지 않는 것은 불가능하다. 하지만 최대한 의존하지 않으면서 모델을 학습시키고자 노력한다.) 2. IN와 같이 **appearance invariance 성질을 가진 Layer 를 찾아** 모델에 넣었다. - Method  # 1.1 **읽어야할 다음 논문 List** 1. IN을 사용해서 individual contrast를 제거함으로써 Style transfer를 수행하는 논문들 - (#NO 핵심이 없고 메소드도 명확하지 않고 이해가 안된다) Improved texture networks: Maximizing quality and diversity in feed-forward stylization and texture synthesis. CVPR (2017) - (#13) A learned representation for artistic style. ICLR (2017) - (#14) Arbitrary style transfer in real-time with adaptive instance normalization. ICCV (2017) 2. 다양한 Adpatation 기법들 - (#2) AdaBN: Adaptive Batch Normalization - MMD: (#3) Deep Domain Confusion: Maximizing for Domain Invariance, (#4) Learning Transferable Features with Deep Adaptation Networks - CORAL: (#5) Deep coral- correlation (covariance) alignment for deep domain adaptation 3. DG 논문들 - (#7) Undoing the damage of dataset bias. ECCV (2012) - (#8) Domain generalization via invariant feature representation. ICML (2013) - (#9) Domain generalization for object recognition with multi-task autoencoders. ICCV (2015) 4. 참고사항!! - feature correlations matrix := covariance matrix := feature dot similarity := a gram matrix - Instacne Normalization을 해주고 feature dot similarity matrix == correlations matrix - 헷갈리지만, 다 비슷비슷하다. 코드를 보면서 필요한 것을 사용하자. # 1.2. DA: AdaBN -arXiv16  - "Label(Contents) 와 관련된 내용은 Conv/FC의 weight에 저장되어 있고, Domain 에 관련된 내용은 BN에 저장되어 있다는 가설"을 제시한다. - 새로운 Domain Dataset에 대해 위 알고리즘 방법을 사용해서 BN mean, standard diviation를 바꿔, 모델 Transfer를 진행한다. - 이미 학습된 γ (감마) and β (배타) 에는 이미 Source 의 Style이 남아있으니... mean, standard diviation 이라도!! Target **전체** 이미지의 평균, 표준편차값을 이용하여 Target domain에 그나마 적절한 BN을 수행하겠다. - (Me: Conv/FC의 weight에 Invariance 성질을 어떻게 넣을까??) # 1.3. DA: Maximizing for Domain Invariance -arXiv14  - `Additional domain confusion Loss` == `domain confusion metric` == `MMD` - 이미지 feature 각각의 (1대1 매칭) 거리 비교는 아니고, 데이터셋 전체의 Feature Centroids를 비교해서 domain confusion을 구한다. 이미지 아래 수식 참조. - domain confusion 이 최소화 되도록 Model 에 Loss를 준다. 또한 domain confusion 계산값을 이용해 feature를 뽑아야하는 layer와 fc-dimmension을 설정한다. # 1.4. DA: MK-MMD -ICML15  Paper: Learning Transferable Features with Deep Adaptation Networks - Deep Adaptation Network (DAN) - [reproducing kernel Hilbert space](https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=sw4r&logNo=221491666976) (RKHS) 개념을 사용해서, 기존의 MMD를 multiple kernel variant of MMD (MK-MMD) 으로 바꿔 사용 - Feature map 그대로에 대한 Distance를 비교하는 것이 아니라, Feature에 특정한 kernal (다양한 종류의 행렬변환/ 비선형 변환등 모두 가능) 을 적용해 새로운 Feature를 만들고 그것에 대해서 Distance를 비교한다. 이때 Kernel은 [PSD kernal](https://en.wikipedia.org/wiki/Positive-definite_kernel)을 사용한다고 한다, ->> 딥한 수학적 내용이어서 이해는 이정도만 하자. - 위의 수학 수식과 개념은 복잡해도, 코드를 확인해보면 별거 없다. Source와 Target Feature에 Gaussian_kernel을 적용하고 두개의 Distance를 비교하는듯 하다. [MK-MMD](https://github.com/ZhaoZhibin/UDTL/blob/master/loss/DAN.py) # 1.5. UDA: Correlation alignment -ECCV16  - [CORAL Loss 코드 링크](https://github.com/ZhaoZhibin/UDTL/blob/master/loss/CORAL.py) ([frustratingly easy domain adaptation](https://arxiv.org/pdf/0907.1815.pdf) - 2009): "각 Domain의 Feature들 사이의 공분산" 차이를 최소화하여, UDA 하고자 한다. 위 이미지에서 [위 파란색 박스 공분산 수식] 보다는 [아래 파란색 박스 공분산 수식]을 보고 코드와 비교해서 이해하도록 하자. 아래 공분산 수식에서 X_k 가 k번째 이미지의 Feature를 의미한다. - 주의!!! 이것말고 아래 논문들이 CORAL은 Channel-wise 이다. 이 논문에서는 1 Image 1 vector (N images M dim vector) NxM matrix 를 이용한다. - MMD(1.3) 기법과 유사한 방법이지만, MMD에서는 `Feature들의 평균`을 비교했다면, 이 논문에서는 `Feature들의 공분산` 을 비교한다. MMD(1.3=DDC)기법보다는 강력하고 MK-MMD(1.4=DAN)기법보다는 심플한 방법이다. - (이 이후에, AdaptSeg, ADVENT가 나오면서 Adversarial Learning을 기법을 이용한 Adaptation 기법들이 주를 이루기 시작했다.) # 1.6. UDA: by Backpropagation -14  - gradient reversal layer 가 핵심이다. 기존 Gradient 에 -1 을 곱해서 반대 Gradient를 준다. - AdaptSeg와 Advent 같은 Adversarial learning 과 비슷하면서도 다른 방법이다. Network에 혼란을 주겠다는 같은 목적을 가지고 있지만, Adversarial 처럼 직관적이고 정확한 gradient를 주기에는 무리가 있는 고전방법이다. # 1.7. DG: Undoing dataset bias -ECCV12  - SVM과 Visual world 관점에서 Optimization이 이뤄지기 때문에, CNN과는 다른 관점으로 이해할 필요가 있다. (이 방법론을 차라리 CNN weight로 바꿔 생각해보자. 이해가 더 쉽다.) - 모델을 통해서 학습하고자 하는 것은 2가지 이다. (1) `bias vectors` (2) `visual world weights(=모든 데이터셋을 위한 Main Model)` - 핵심: Dataset에 대한 Bias를 인정하고, 한 Dataset에 특화된 모델(w_i)에서 (1) Bias 성질과 (2) General model W_vw 를 분리해내고자 노력한다. 즉 `모든 Source domains에 대한 공통 weights` 을 학습하고자 노력한다. - IBN-net, RobustNet 관점에서 **Appearnce invariance 성질을 가진 Feature/Model/Weight를 학습하고자 하는 노력**은 동일하다. 하지만 Source datasets에 너무 많이 의존한다는 단점을 가진 과거 기법이다. # 1.8. DG: via invariant feature representation -ICML13  - 이 논문은 (1.4) MK-MMD 에서 Deep Learning 기법이 아닌 고전적인 기법을 사용한 논문이라 이해하면 된다. 또한 MMD는 Source와 Traget을 이용해서 Adaptation 을 수행한다면, 이 논문에서는 Multi-sources 를 사용해서 Multi-Adaptation 모델을 만든다. 이 논문의 저자들은 이것을 Generalization이 이뤄진 것이라 주장한다. 하지만 지금 관점에서는 `domain agnostic representations in terms of ONLY Source domains` 을 학습한다고 느껴진다. - MMD 처럼 어떤 Source Domain의 이미지가 Input으로 들어가든, **Output 값의 평균이 비슷하도록 만든다. 즉 적절한 Kernel을 만들어(학습시켜) G가 Zero가 되도록 만든다.** - Paper key sentences 1. Domain-Invariant Component Analysis (DICA) extracts invariants 2. **minimizing the dissimilarity across domains** 3. preserving the functional relationship between input and output variables 4. Using dimension reduction algorithms including kernel principal component analysis (KPCA) # 1.9. DG: with multi-task autoencoders -ICCV15  - 같은 Class, 다른 Domain의 이미지를 Reconstruction하는 Task를 (서로 다른 Domain에 대해서) Multi로 수행하여 Weight가 Domian General하게 만든다 - 위와 같은 알고리즘으로 만든 W는 Image classification을 위해서 사용된다. - Domain Generalization이라고 하지만, Multi-sources를 활용한 Self-supervised Learning 기법이라고 하는게 맞겠다. 저자는 이 아이디어가 domain invariance에 유용한 Backbone을 만들 수 있을거라 주장한다. 하지만 이 아이디어를 Contrastive Learning과 비교한다면, Contrastive Learning 기법으로 만든 Self-sup-weight 만으로도 충분히 Generalization에 도움이 더 될 것 같다. - Paper key sentences 1. Multi-Task Autoencoder (MTAE) provides good generalization performance. 2. MTAE learns to transform the original image into analogs "in multiple related domains" 3. jointly learns multiple data-reconstruction tasks # 1.11. ST: Perceptual Losses for Real-Time Style Transfer -arXiv16  - Style Transformer의 시작, 유명한 저자(Justin Johnson, Alexandre Alahi, Li Fei-Fei), [RobustNet correlation (covariance) Matric 계산그림](https://junha1125.github.io/blog/artificial-intelligence/2021-05-22-RobustNet/#41-iw-loss-instance-whitening-loss), dot_similarity != correlation (covariance) 서로 다르니 주의하자. - Feature Reconstruction Loss - Euclidean distance, Contenct 를 유지하도록 만든다. - Higer layers 에서 Loss를 적용하기 때문에, `Content and overall spatial structure` 는 보존하면서 `color, texture` 는 따라하지 않도록 만든다. - Style Reconstruction Loss - `style: colors, textures, common patterns` 만을 따라하도록 만든다. - Gram matrices(=Channel Wise dot_similarity matrices)의 Frobenius norm (L2-norm) 차이(로스)가 작아지도록 유도한다. - [Gram matrices 계산 코드](https://github.com/dxyang/StyleTransfer/blob/master/utils.py#L22) - Style Loss를 처음 제안한 논문 (아래 논문을 통해서 RobustNet에서 주장한 "**correlation (covariance) Matrix가 Style 정보를 담고 있다**"라는 가설에 대해 분석해볼 수 있겠다) - (DG survey2 참조) Texture synthesis using convolutional neural networks - (DG survey2 참조) A neural algorithm of artistic style # 1.12. ST: Instance Normalization -arXiv16 - Paper: [Instance Normalization: The Missing Ingredient for Fast Stylization](https://arxiv.org/pdf/1607.08022.pdf) - 바로 위 논문과는 조금 다른 형태의 Generator를 가지며 비슷한 시기에 나온 [Style transform 논문](https://arxiv.org/pdf/1603.03417.pdf). 심플하게 이 안에서 BN들을 IN으로 바꿨다. - Style Transfer의 기본 모델들은 ImageNet으로 Pretrained 된 network를 사용했다. 그래서 BN을 그대로 사용한다. - IN를 사용함으로써, Sample/Image/Instance에 특화된 Feature를 유지하게 해주어, 더 좋은 Style Transform이 가능하게 한다. # 1.13. ST: Learned Representation For Artistic Style -ICLR17   - 이용할 만한 핵심 내용 - **Style Transfer Network 에서, Style에 영향을 주는 파라미터는 γ (감마) and β (배타) 이다.** 그 외 Conv layer의 파라미터는 거의 영향을 미치지 않는다. - 따라서 영향이 적은 파라미터는 완전히 고정시키고, 스타일 마다 다른 γ (감마) and β (배타) 를 학습시키고, γ (감마) and β (배타) 를 다르게 설정하는 것 만으로, 놀랍게도 다른 스타일의 이미지를 쉽게 생성할 수 있다. - 논문 내용 정리 1. (1.11) Old style transfer 모델은 하나의 transfer network가 하나의 스타일만 만들 수 있는 `single-purpose nature` 문제점이 존재했다. 이 논문은 이러한 문제를 해결하고자 한다. 각 스타일을 만드는 모델들이 비슷한 파라미터 값을 가지는 것이 확인하고 연구가 시작되었다. 2. 원하는 Style을 조건적으로 선택하여 하나의 Style Tansfer가 N개의 Style을 생성할 수 있는 Network를 만든다.( `conditional style transfer network`) 선택적으로 감마와 베타를 고르는 작업을 `conditional instance normalization` 이라고 표현한다. 3. 새로운 Style에 대한 Style transfer network를 만들고 싶다면, conv와 같은 Layer는 놔두고 γ (감마) and β (배타) 만 학습시키면 되니, 학습도 매우 빠르게 가능하다. # 1.14. ST: Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization -ICCV17  이 논문의 핵심은 위 (1.13)과 동일하다. (1.13) 과의 핵심 차이점은 (learnable parameter) γ (감마) and β (배타) 를 ->> (No learnable parameter) standard_deviation( y ), Mean( y ) 로 바꾼것이다. 하지만 이 논문이 해석과 분석을 완벽하게 하였다. 그래서 내가 "왜 IN을 통해서 저런 효과를 얻을 수 있는지" 이해할 수 있었다. 매우 좋은 논문이었다. 따라서 정리를 좀 더 완벽하게 할 계획이다. - 문제점과 해결: 지금까지 Style Transfer 기법들은 1개 혹은 N개의 제한된 Style만을 변환할 수 있는 모델들이었다. 이 논문 기법을 통해서 어떤 Style의 이미지가 들어와도 Style Transfer를 수행할 수 있는 모델을 만들었다. `adaptive instance normalization (AdaIN) layer` 가 핵심이다. - `Contents Loss`는 Euclidean distance를 그대로 사용한다. 하지만 `Style Loss`는 아래와 같이 다양한 Loss가 있다. 이렇게 다양한 Loss를 통해서, 나는 `Deep Network에서 Style 정보를 담고 있는 부분`을 정리&분석해 볼 수 있었다. 1. 다양한 종류의 `Style Loss`: MRF loss [30], adversarial loss [31], histogram loss [54], **CORAL loss** [41], MMD loss [33], and **distance between channel-wise mean and variance** [33]. 특히 이 논문에서 사용하는 Loss는 [Distance between channel-wise mean and variance loss (코드링크)](https://github.com/naoto0804/pytorch-AdaIN/blob/master/net.py#L130) 이다. 하지만 Gram matrix 를 사용해도 비슷한 성능이 나왔다고 한다. (따라서 Distance 와 gram 은 Style 정보를 비슷하게 가지고 있겠구나!) 2. `Deep Network에서 Style 정보를 담고 있는 부분` (내가 이용할 만한 내용 분석) 1. IN 의 파라미터 값 2. Channel-wise dot_similarity Matrix = [Gram matrices](https://github.com/dxyang/StyleTransfer/blob/master/utils.py#L22) 3. Channel-wise correlation (covariance) Matrix (in [CORAL](https://github.com/ZhaoZhibin/UDTL/blob/master/loss/CORAL.py), RobustNet) 4. Channel-wise mean and variance - `이 논문이 IN에 대해 분석한 핵심` 1. "IN은 Feature를 Normalization함으로써 일종의 `style normalization` 을 수행한다. 즉, 어떤 Style이 들어와도 Normalize하여 (적절한 위치로 이동시키는 것을 도와주어), Network가 빨리 수렴되고 Style Invariance 를 가지게 도와준다. 2. 반대로 BN은 한 Batch의 이미지를 하나의 Style로 Normalize 해버린다. 그래서 Style Transfer Network가 학습되는 동안 Batch 속 이미지 각각이 자신의 Content와 Style을 유지하는데 방해를 주어, 학습 수렴이 잘 안되게 만든다. 3. 논문의 Figure1을 통해서 IN의 성질에 대해 증명하였다. (증명과 실험 내용은 필요하면 참고. 핵심만 적어 놓는다)
